 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Mixed Optimization for Reinforcement Learning with Program Synthesis
Paper and Code
Jul 03, 2018
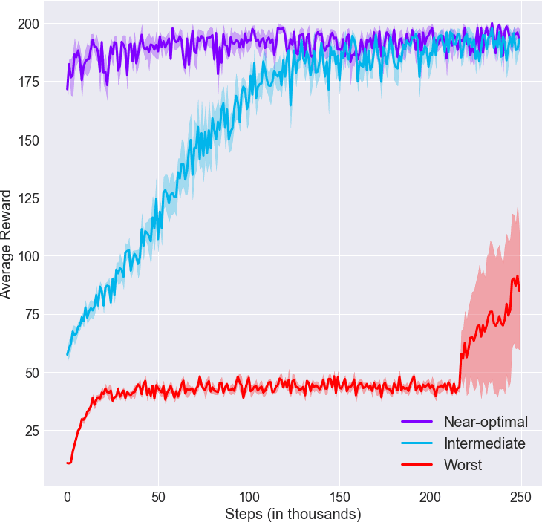
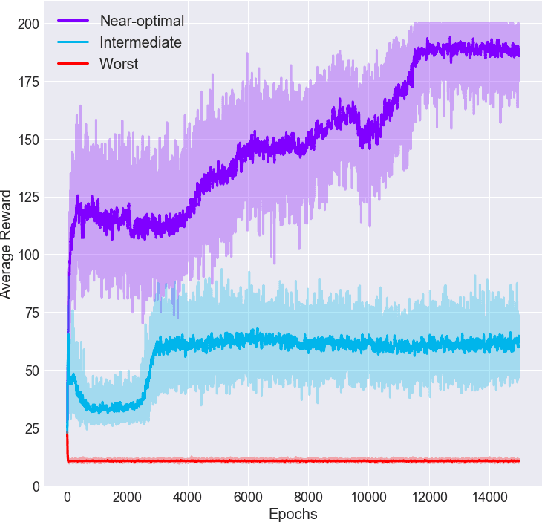
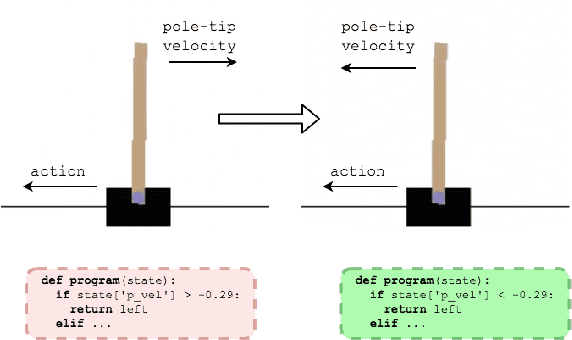
Deep reinforcement learning has led to several recent breakthroughs, though the learned policies are often based on black-box neural networks. This makes them difficult to interpret and to impose desired specification constraints during learning. We present an iterative framework, MORL, for improving the learned policies using program synthesis. Concretely, we propose to use synthesis techniques to obtain a symbolic representation of the learned policy, which can then be debugged manually or automatically using program repair. After the repair step, we use behavior cloning to obtain the policy corresponding to the repaired program, which is then further improved using gradient descent. This process continues until the learned policy satisfies desired constraints. We instantiate MORL for the simple CartPole problem and show that the programmatic representation allows for high-level modifications that in turn lead to improved learning of the policies.