 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Language Modelling in the Speech Domain Using Sub-word Linguistic Units
Paper and Code
Oct 31, 2021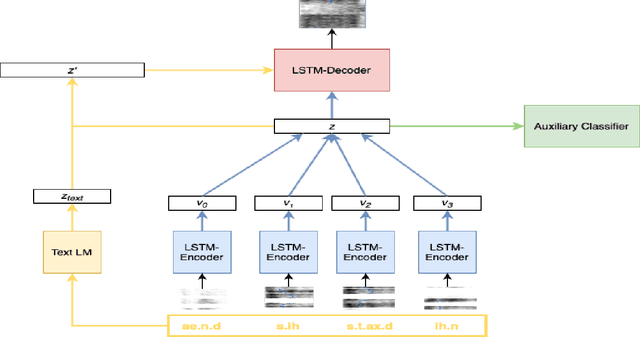

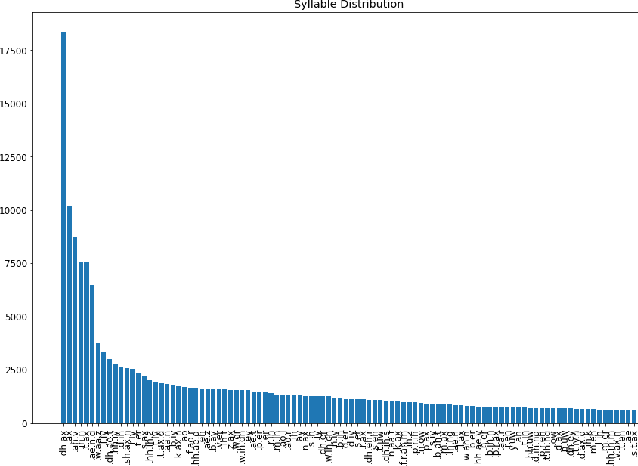
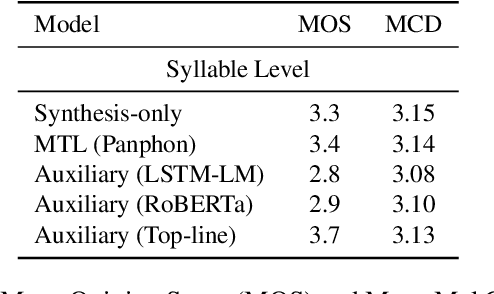
Language models (LMs) for text data have been studied extensively for their usefulness in language generation and other downstream tasks. However, language modelling purely in the speech domain is still a relatively unexplored topic, with traditional speech LMs often depending on auxiliary text LMs for learning distributional aspects of the language. For the English language, these LMs treat words as atomic units, which presents inherent challenges to language modelling in the speech domain. In this paper, we propose a novel LSTM-based generative speech LM that is inspired by the CBOW model and built on linguistic units including syllables and phonemes. This offers better acoustic consistency across utterances in the dataset, as opposed to single melspectrogram frames, or whole words. With a limited dataset, orders of magnitude smaller than that required by contemporary generative models, our model closely approximates babbling speech. We show the effect of training with auxiliary text LMs, multitask learning objectives, and auxiliary articulatory features. Through our experiments, we also highlight some well known, but poorly documented challenges in training generative speech LMs, including the mismatch between the supervised learning objective with which these models are trained such as Mean Squared Error (MSE), and the true objective, which is speech quality. Our experiments provide an early indication that while validation loss and Mel Cepstral Distortion (MCD) are not strongly correlated with generated speech quality, traditional text language modelling metrics like perplexity and next-token-prediction accuracy might be.