 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable Surgical Activity Recognition Using Spatial Temporal Graph Convolutional Networks
Paper and Code

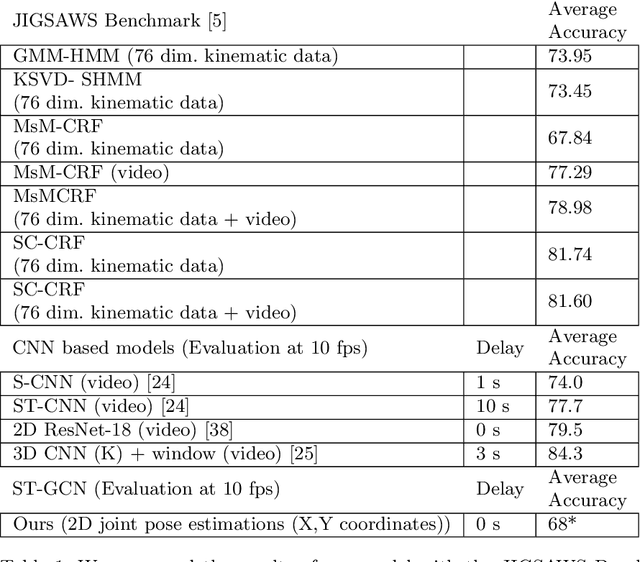

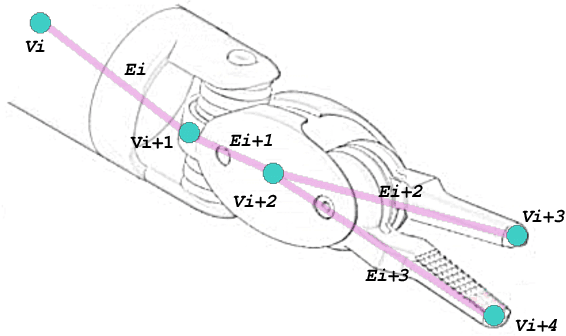
Purpose Modeling and recognition of surgical activities poses an interesting research problem. Although a number of recent works studied automatic recognition of surgical activities, generalizability of these works across different tasks and different datasets remains a challenge. We introduce a modality that is robust to scene variation, based on spatial temporal graph representations of surgical tools in videos for surgical activity recognition. Methods To show its effectiveness, we model and recognize surgical gestures with the proposed modality. We construct spatial graphs connecting the joint pose estimations of surgical tools. Then, we connect each joint to the corresponding joint in the consecutive frames forming inter-frame edges representing the trajectory of the joint over time. We then learn hierarchical spatial temporal graph representations using Spatial Temporal Graph Convolutional Networks (ST-GCN). Results Our experimental results show that learned spatial temporal graph representations of surgical videos perform well in surgical gesture recognition even when used individually. We experiment with the Suturing task of the JIGSAWS dataset where the chance baseline for gesture recognition is 10%. Our results demonstrate 68% average accuracy which suggests a significant improvement. Conclusions Our experimental results show that our model learns meaningful representations.These learned representations can be used either individually, in cascades or as a complementary modality in surgical activity recognition, therefore provide a benchmark. To our knowledge, our paper is the first to use spatial temporal graph representations based on pose estimations of surgical tools in surgical activity recognition.