 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deeper Deep Reinforcement Learning
Paper and Code
Jun 02, 2021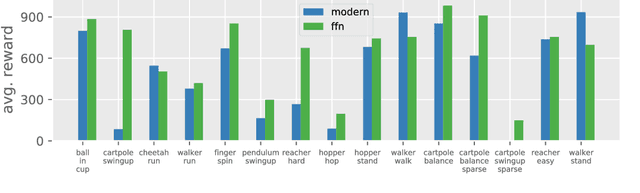
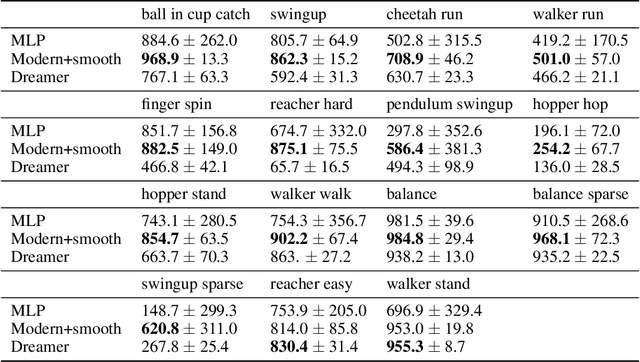
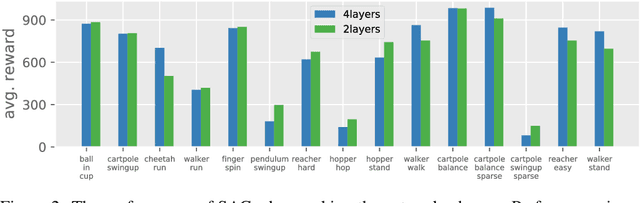

In computer vision and natural language processing, innovations in model architecture that lead to increases in model capacity have reliably translated into gains in performance. In stark contrast with this trend, state-of-the-art reinforcement learning (RL) algorithms often use only small MLPs, and gains in performance typically originate from algorithmic innovations. It is natural to hypothesize that small datasets in RL necessitate simple models to avoid overfitting; however, this hypothesis is untested. In this paper we investigate how RL agents are affected by exchanging the small MLPs with larger modern networks with skip connections and normalization, focusing specifically on soft actor-critic (SAC) algorithms. We verify, empirically, that na\"ively adopting such architectures leads to instabilities and poor performance, likely contributing to the popularity of simple models in practice. However, we show that dataset size is not the limiting factor, and instead argue that intrinsic instability from the actor in SAC taking gradients through the critic is the culprit. We demonstrate that a simple smoothing method can mitigate this issue, which enables stable training with large modern architectures. After smoothing, larger models yield dramatic performance improvements for state-of-the-art agents -- suggesting that more "easy" gains may be had by focusing on model architectures in addition to algorithmic innovations.