 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Agnostic Feature-based Dynamic Pricing: Linear Policies vs Linear Valuation with Unknown Noise
Paper and Code
Jan 27, 2022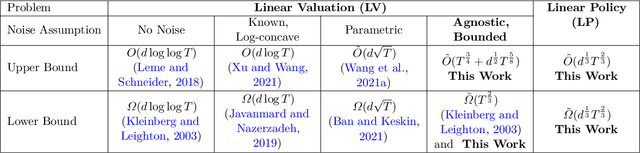
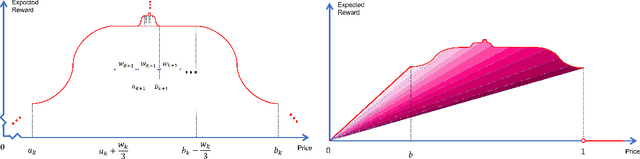
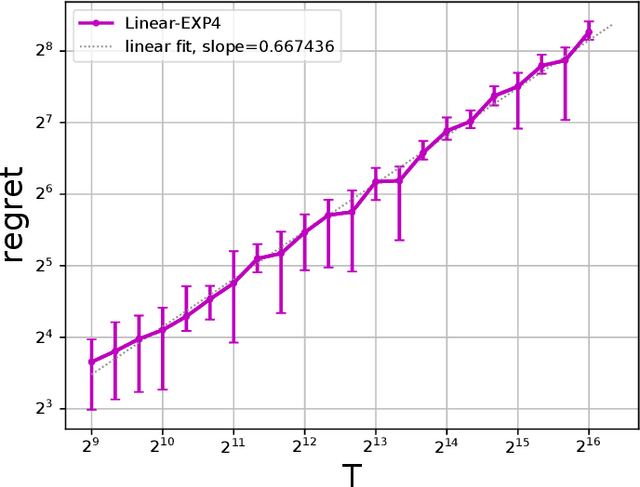
In feature-based dynamic pricing, a seller sets appropriate prices for a sequence of products (described by feature vectors) on the fly by learning from the binary outcomes of previous sales sessions ("Sold" if valuation $\geq$ price, and "Not Sold" otherwise). Existing works either assume noiseless linear valuation or precisely-known noise distribution, which limits the applicability of those algorithms in practice when these assumptions are hard to verify. In this work, we study two more agnostic models: (a) a "linear policy" problem where we aim at competing with the best linear pricing policy while making no assumptions on the data, and (b) a "linear noisy valuation" problem where the random valuation is linear plus an unknown and assumption-free noise. For the former model, we show a $\tilde{\Theta}(d^{\frac13}T^{\frac23})$ minimax regret up to logarithmic factors. For the latter model, we present an algorithm that achieves an $\tilde{O}(T^{\frac34})$ regret, and improve the best-known lower bound from $\Omega(T^{\frac35})$ to $\tilde{\Omega}(T^{\frac23})$. These results demonstrate that no-regret learning is possible for feature-based dynamic pricing under weak assumptions, but also reveal a disappointing fact that the seemingly richer pricing feedback is not significantly more useful than the bandit-feedback in regret reduction.