 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Active Vision for Action Localization with Reactive Control and Predictive Learning
Paper and Code
Nov 09, 2021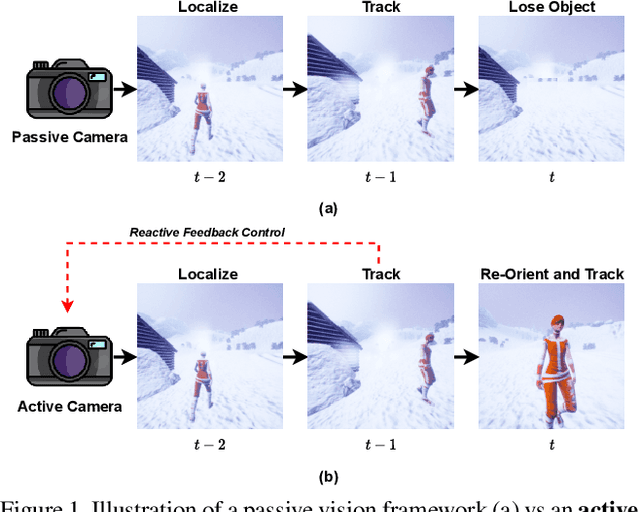
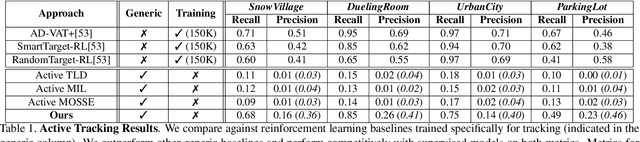
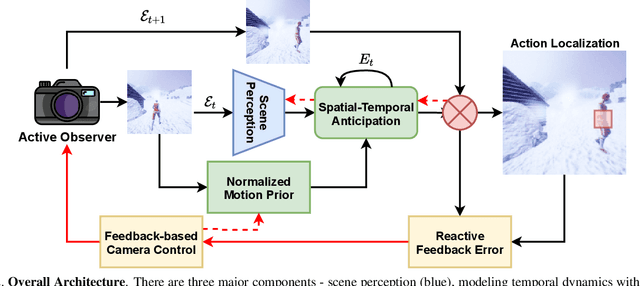
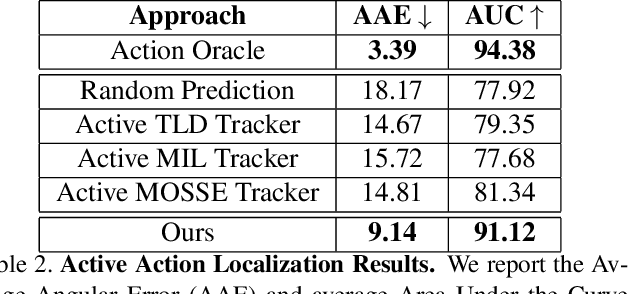
Visual event perception tasks such as action localization have primarily focused on supervised learning settings under a static observer, i.e., the camera is static and cannot be controlled by an algorithm. They are often restricted by the quality, quantity, and diversity of \textit{annotated} training data and do not often generalize to out-of-domain samples. In this work, we tackle the problem of active action localization where the goal is to localize an action while controlling the geometric and physical parameters of an active camera to keep the action in the field of view without training data. We formulate an energy-based mechanism that combines predictive learning and reactive control to perform active action localization without rewards, which can be sparse or non-existent in real-world environments. We perform extensive experiments in both simulated and real-world environments on two tasks - active object tracking and active action localization. We demonstrate that the proposed approach can generalize to different tasks and environments in a streaming fashion, without explicit rewards or training. We show that the proposed approach outperforms unsupervised baselines and obtains competitive performance compared to those trained with reinforcement learning.