 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Abstract Relational Learning in Human Robot Interaction
Paper and Code
Nov 20, 2020
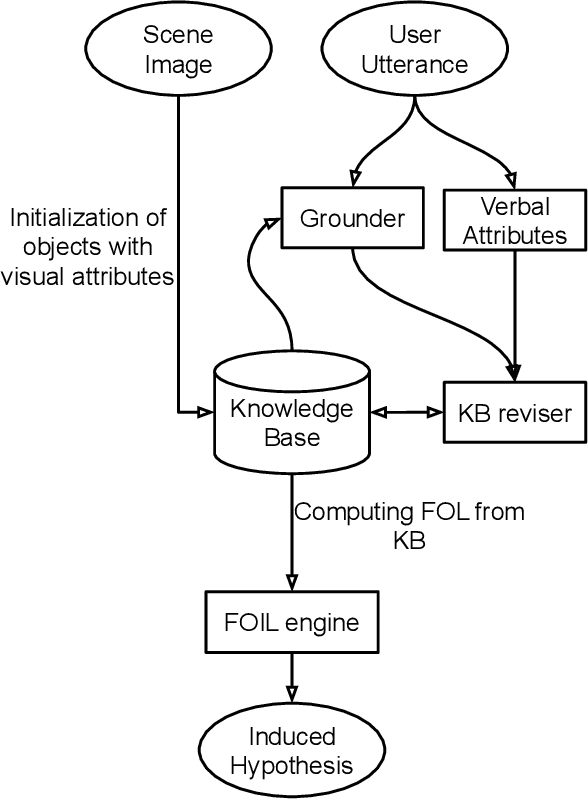


Humans have a rich representation of the entities in their environment. Entities are described by their attributes, and entities that share attributes are often semantically related. For example, if two books have "Natural Language Processing" as the value of their `title' attribute, we can expect that their `topic' attribute will also be equal, namely, "NLP". Humans tend to generalize such observations, and infer sufficient conditions under which the `topic' attribute of any entity is "NLP". If robots need to interact successfully with humans, they need to represent entities, attributes, and generalizations in a similar way. This ends in a contextualized cognitive agent that can adapt its understanding, where context provides sufficient conditions for a correct understanding. In this work, we address the problem of how to obtain these representations through human-robot interaction. We integrate visual perception and natural language input to incrementally build a semantic model of the world, and then use inductive reasoning to infer logical rules that capture generic semantic relations, true in this model. These relations can be used to enrich the human-robot interaction, to populate a knowledge base with inferred facts, or to remove uncertainty in the robot's sensory inputs.