 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a performance analysis on pre-trained Visual Question Answering models for autonomous driving
Paper and Code
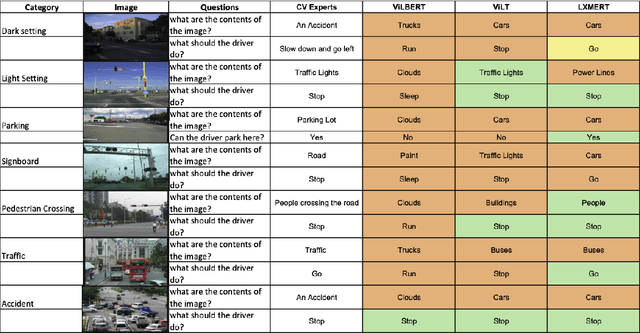
This short paper presents a preliminary analysis of three popular Visual Question Answering (VQA) models, namely ViLBERT, ViLT, and LXMERT, in the context of answering questions relating to driving scenarios. The performance of these models is evaluated by comparing the similarity of responses to reference answers provided by computer vision experts. Model selection is predicated on the analysis of transformer utilization in multimodal architectures. The results indicate that models incorporating cross-modal attention and late fusion techniques exhibit promising potential for generating improved answers within a driving perspective. This initial analysis serves as a launchpad for a forthcoming comprehensive comparative study involving nine VQA models and sets the scene for further investigations into the effectiveness of VQA model queries in self-driving scenarios. Supplementary material is available at https://github.com/KaavyaRekanar/Towards-a-performance-analysis-on-pre-trained-VQA-models-for-autonomous-driving.