 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Hypothesis on Visual Transformation based Self-Supervision
Paper and Code
Nov 24, 2019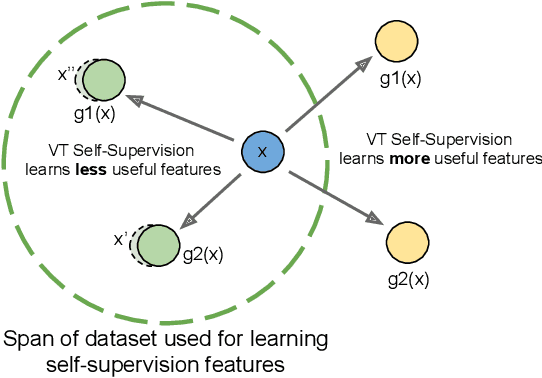
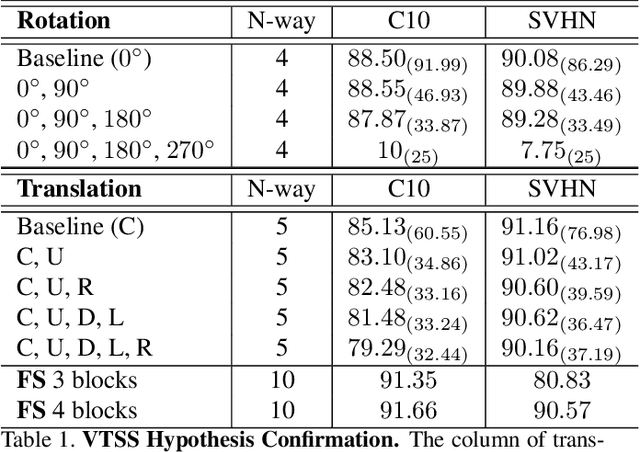
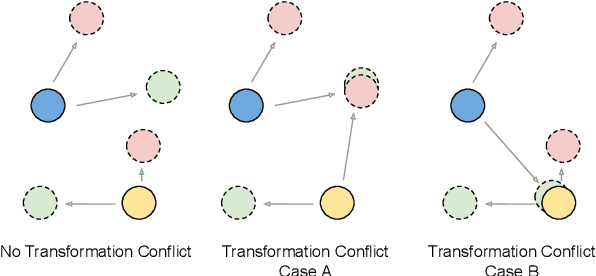
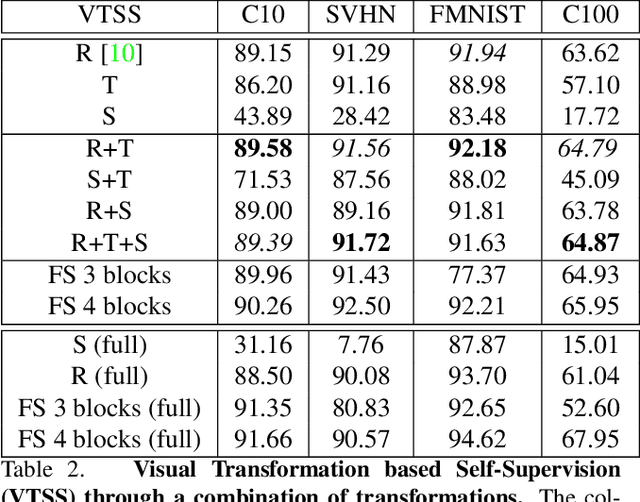
We propose the first qualitative hypothesis characterizing the behavior of visual transformation based self-supervision, called the VTSS hypothesis. Given a dataset upon which a self-supervised task is performed while predicting instantiations of a transformation, the hypothesis states that if the predicted instantiations of the transformations are already present in the dataset, then the representation learned will be less useful. The hypothesis was derived by observing a key constraint in the application of self-supervision using a particular transformation. This constraint, which we term the transformation conflict for this paper, forces a network learn degenerative features thereby reducing the usefulness of the representation. The VTSS hypothesis helps us identify transformations that have the potential to be effective as a self-supervision task. Further, it helps to generally predict whether a particular transformation based self-supervision technique would be effective or not for a particular dataset. We provide extensive evaluations on CIFAR 10, CIFAR 100, SVHN and FMNIST confirming the hypothesis and the trends it predicts. We also propose novel cost-effective self-supervision techniques based on translation and scale, which when combined with rotation outperforms all transformations applied individually. Overall, this paper aims to shed light on the phenomenon of visual transformation based self-supervision.