 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a framework for evaluating the safety, acceptability and efficacy of AI systems for health: an initial synthesis
Paper and Code
Apr 14, 2021
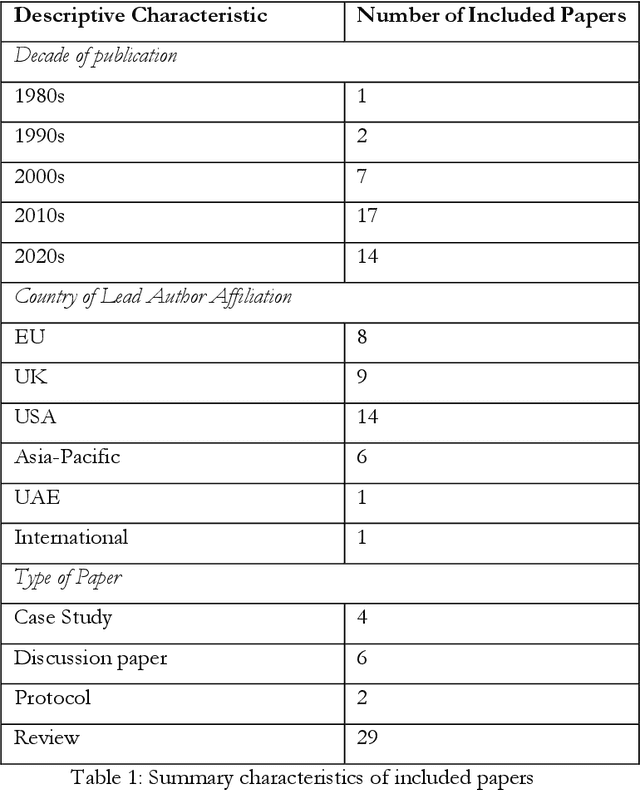
The potential presented by Artificial Intelligence (AI) for healthcare has long been recognised by the technical community. More recently, this potential has been recognised by policymakers, resulting in considerable public and private investment in the development of AI for healthcare across the globe. Despite this, excepting limited success stories, real-world implementation of AI systems into front-line healthcare has been limited. There are numerous reasons for this, but a main contributory factor is the lack of internationally accepted, or formalised, regulatory standards to assess AI safety and impact and effectiveness. This is a well-recognised problem with numerous ongoing research and policy projects to overcome it. Our intention here is to contribute to this problem-solving effort by seeking to set out a minimally viable framework for evaluating the safety, acceptability and efficacy of AI systems for healthcare. We do this by conducting a systematic search across Scopus, PubMed and Google Scholar to identify all the relevant literature published between January 1970 and November 2020 related to the evaluation of: output performance; efficacy; and real-world use of AI systems, and synthesising the key themes according to the stages of evaluation: pre-clinical (theoretical phase); exploratory phase; definitive phase; and post-market surveillance phase (monitoring). The result is a framework to guide AI system developers, policymakers, and regulators through a sufficient evaluation of an AI system designed for use in healthcare.