 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Understanding the Disagreement Problem in Neural Network Feature Attribution
Paper and Code
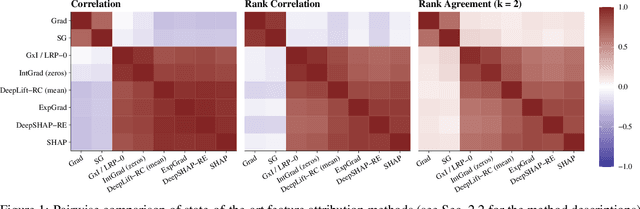

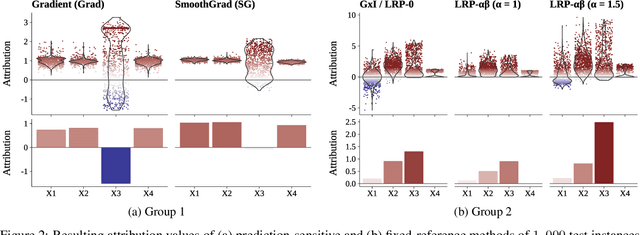

In recent years, neural networks have demonstrated their remarkable ability to discern intricate patterns and relationships from raw data. However, understanding the inner workings of these black box models remains challenging, yet crucial for high-stake decisions. Among the prominent approaches for explaining these black boxes are feature attribution methods, which assign relevance or contribution scores to each input variable for a model prediction. Despite the plethora of proposed techniques, ranging from gradient-based to backpropagation-based methods, a significant debate persists about which method to use. Various evaluation metrics have been proposed to assess the trustworthiness or robustness of their results. However, current research highlights disagreement among state-of-the-art methods in their explanations. Our work addresses this confusion by investigating the explanations' fundamental and distributional behavior. Additionally, through a comprehensive simulation study, we illustrate the impact of common scaling and encoding techniques on the explanation quality, assess their efficacy across different effect sizes, and demonstrate the origin of inconsistency in rank-based evaluation metrics.