 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Effective Automated Content Analysis via Crowdsourcing
Paper and Code
Jan 12, 2021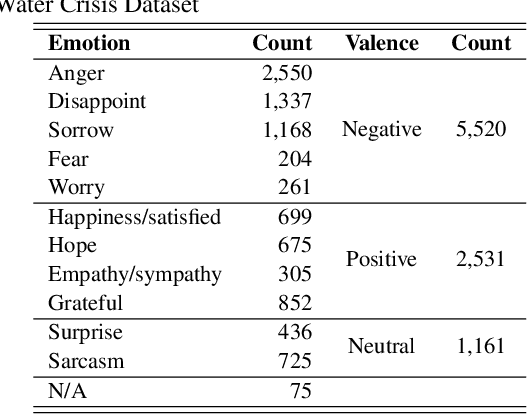
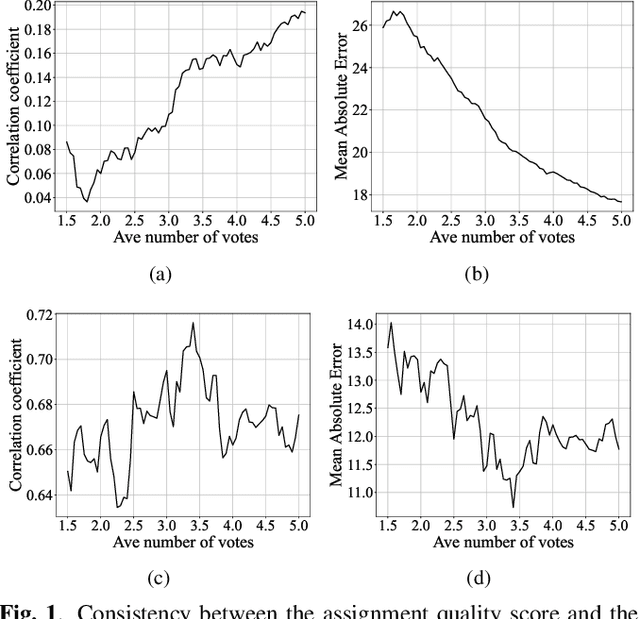
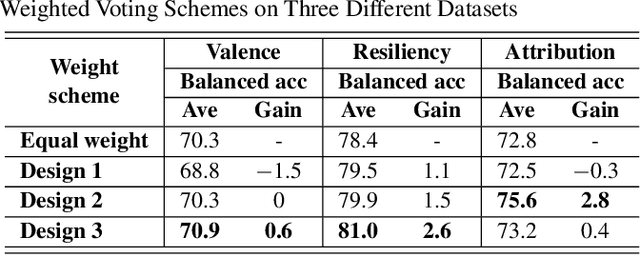
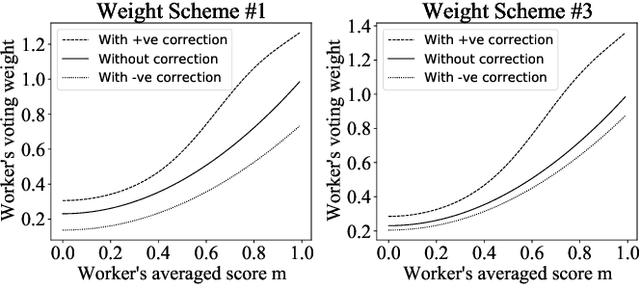
Many computer scientists use the aggregated answers of online workers to represent ground truth. Prior work has shown that aggregation methods such as majority voting are effective for measuring relatively objective features. For subjective features such as semantic connotation, online workers, known for optimizing their hourly earnings, tend to deteriorate in the quality of their responses as they work longer. In this paper, we aim to address this issue by proposing a quality-aware semantic data annotation system. We observe that with timely feedback on workers' performance quantified by quality scores, better informed online workers can maintain the quality of their labeling throughout an extended period of time. We validate the effectiveness of the proposed annotation system through i) evaluating performance based on an expert-labeled dataset, and ii) demonstrating machine learning tasks that can lead to consistent learning behavior with 70%-80% accuracy. Our results suggest that with our system, researchers can collect high-quality answers of subjective semantic features at a large scale.