 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Communication Efficient Adaptive Gradient Method
Paper and Code
Sep 10, 2021
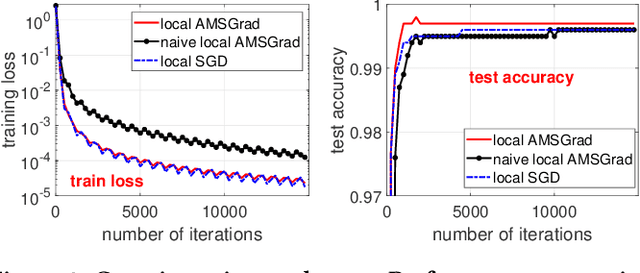


In recent years, distributed optimization is proven to be an effective approach to accelerate training of large scale machine learning models such as deep neural networks. With the increasing computation power of GPUs, the bottleneck of training speed in distributed training is gradually shifting from computation to communication. Meanwhile, in the hope of training machine learning models on mobile devices, a new distributed training paradigm called ``federated learning'' has become popular. The communication time in federated learning is especially important due to the low bandwidth of mobile devices. While various approaches to improve the communication efficiency have been proposed for federated learning, most of them are designed with SGD as the prototype training algorithm. While adaptive gradient methods have been proven effective for training neural nets, the study of adaptive gradient methods in federated learning is scarce. In this paper, we propose an adaptive gradient method that can guarantee both the convergence and the communication efficiency for federated learning.