 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Abstraction from Multi-modal Data: Empirical Studies on Multiple Time-scale Recurrent Models
Paper and Code
Feb 07, 2017
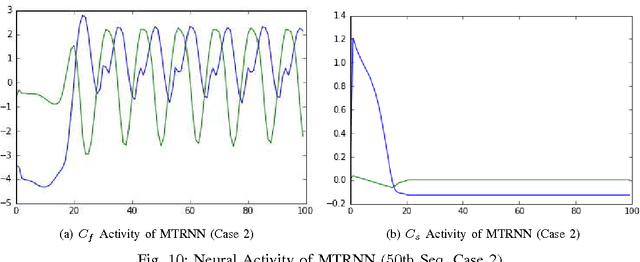
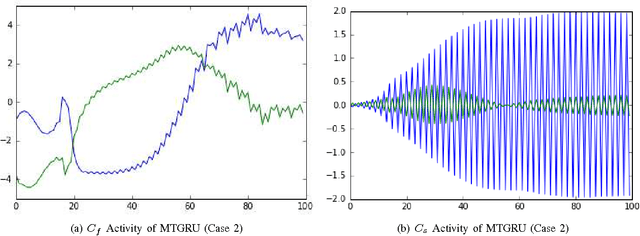

The abstraction tasks are challenging for multi- modal sequences as they require a deeper semantic understanding and a novel text generation for the data. Although the recurrent neural networks (RNN) can be used to model the context of the time-sequences, in most cases the long-term dependencies of multi-modal data make the back-propagation through time training of RNN tend to vanish in the time domain. Recently, inspired from Multiple Time-scale Recurrent Neural Network (MTRNN), an extension of Gated Recurrent Unit (GRU), called Multiple Time-scale Gated Recurrent Unit (MTGRU), has been proposed to learn the long-term dependencies in natural language processing. Particularly it is also able to accomplish the abstraction task for paragraphs given that the time constants are well defined. In this paper, we compare the MTRNN and MTGRU in terms of its learning performances as well as their abstraction representation on higher level (with a slower neural activation). This was done by conducting two studies based on a smaller data- set (two-dimension time sequences from non-linear functions) and a relatively large data-set (43-dimension time sequences from iCub manipulation tasks with multi-modal data). We conclude that gated recurrent mechanisms may be necessary for learning long-term dependencies in large dimension multi-modal data-sets (e.g. learning of robot manipulation), even when natural language commands was not involved. But for smaller learning tasks with simple time-sequences, generic version of recurrent models, such as MTRNN, were sufficient to accomplish the abstraction task.