 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIP: Typifying the Interpretability of Procedures
Paper and Code
Oct 29, 2018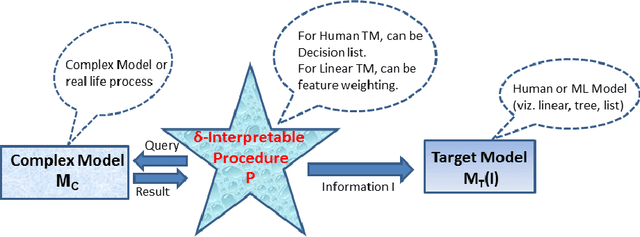
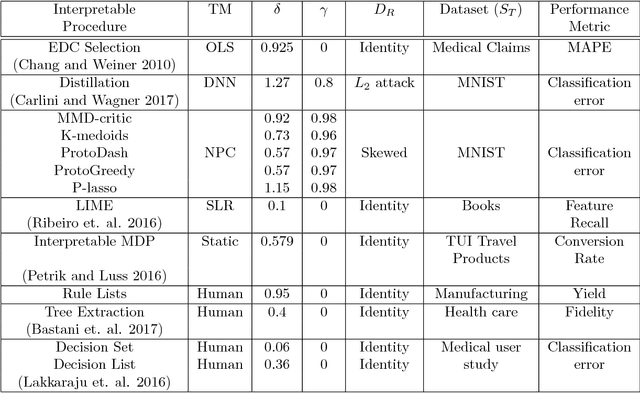
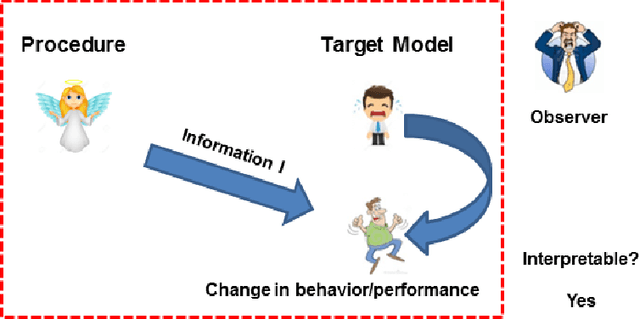

We provide a novel notion of what it means to be interpretable, looking past the usual association with human understanding. Our key insight is that interpretability is not an absolute concept and so we define it relative to a target model, which may or may not be a human. We define a framework that allows for comparing interpretable procedures by linking them to important practical aspects such as accuracy and robustness. We characterize many of the current state-of-the-art interpretable methods in our framework portraying its general applicability. Finally, principled interpretable strategies are proposed and empirically evaluated on synthetic data, as well as on the largest public olfaction dataset that was made recently available \cite{olfs}. We also experiment on MNIST with a simple target model and different oracle models of varying complexity. This leads to the insight that the improvement in the target model is not only a function of the oracle model's performance, but also its relative complexity with respect to the target model. Further experiments on CIFAR-10, a real manufacturing dataset and FICO dataset showcase the benefit of our methods over Knowledge Distillation when the target models are simple and the complex model is a neural network.