 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime out of Mind: Generating Rate of Speech conditioned on emotion and speaker
Paper and Code
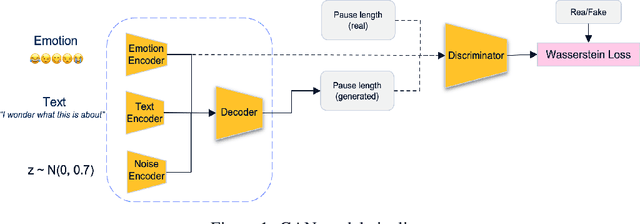
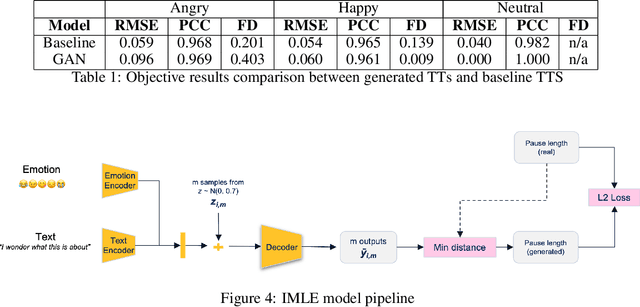
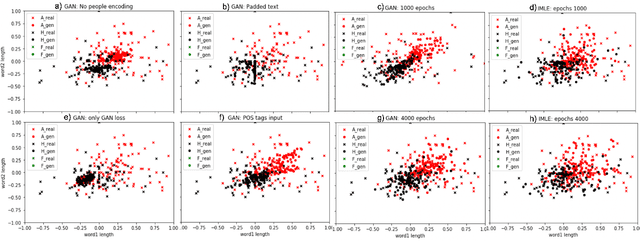
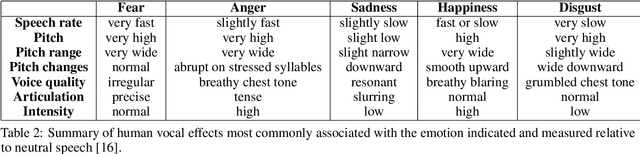
Voice synthesis has seen significant improvements in the past decade resulting in highly intelligible voices. Further investigations have resulted in models that can produce variable speech, including conditional emotional expression. The problem lies, however, in a focus on phrase-level modifications and prosodic vocal features. Using the CREMA-D dataset we have trained a GAN conditioned on emotion to generate worth lengths for a given input text. These word lengths are relative to neutral speech and can be provided, through speech synthesis markup language (SSML) to a text-to-speech (TTS) system to generate more expressive speech. Additionally, a generative model is also trained using implicit maximum likelihood estimation (IMLE) and a comparative analysis with GANs is included. We were able to achieve better performances on objective measures for neutral speech, and better time alignment for happy speech when compared to an out-of-box model. However, further investigation of subjective evaluation is required.