 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight Regret Bounds for Stochastic Combinatorial Semi-Bandits
Paper and Code
Jan 27, 2015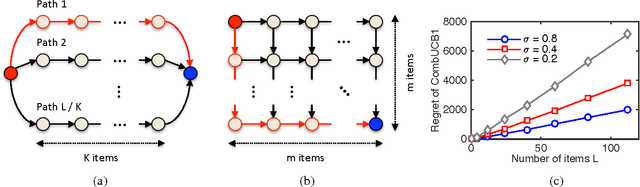
A stochastic combinatorial semi-bandit is an online learning problem where at each step a learning agent chooses a subset of ground items subject to constraints, and then observes stochastic weights of these items and receives their sum as a payoff. In this paper, we close the problem of computationally and sample efficient learning in stochastic combinatorial semi-bandits. In particular, we analyze a UCB-like algorithm for solving the problem, which is known to be computationally efficient; and prove $O(K L (1 / \Delta) \log n)$ and $O(\sqrt{K L n \log n})$ upper bounds on its $n$-step regret, where $L$ is the number of ground items, $K$ is the maximum number of chosen items, and $\Delta$ is the gap between the expected returns of the optimal and best suboptimal solutions. The gap-dependent bound is tight up to a constant factor and the gap-free bound is tight up to a polylogarithmic factor.