 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight Nonparametric Convergence Rates for Stochastic Gradient Descent under the Noiseless Linear Model
Paper and Code
Jun 15, 2020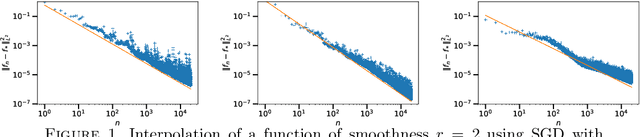

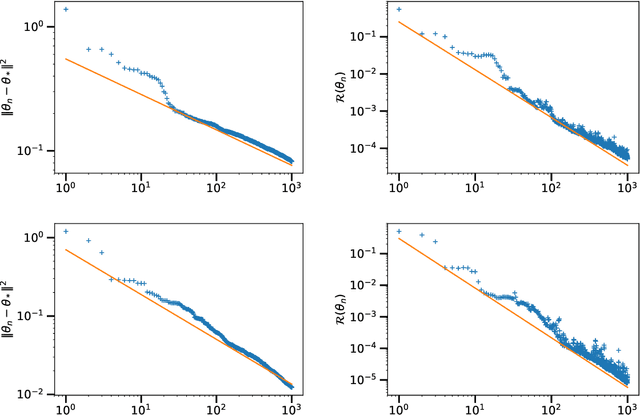

In the context of statistical supervised learning, the noiseless linear model assumes that there exists a deterministic linear relation $Y = \langle \theta_*, X \rangle$ between the random output $Y$ and the random feature vector $\Phi(U)$, a potentially non-linear transformation of the inputs $U$. We analyze the convergence of single-pass, fixed step-size stochastic gradient descent on the least-square risk under this model. The convergence of the iterates to the optimum $\theta_*$ and the decay of the generalization error follow polynomial convergence rates with exponents that both depend on the regularities of the optimum $\theta_*$ and of the feature vectors $\Phi(u)$. We interpret our result in the reproducing kernel Hilbert space framework; as a special case, we analyze an online algorithm for estimating a real function on the unit interval from the noiseless observation of its value at randomly sampled points. The convergence depends on the Sobolev smoothness of the function and of a chosen kernel. Finally, we apply our analysis beyond the supervised learning setting to obtain convergence rates for the averaging process (a.k.a. gossip algorithm) on a graph depending on its spectral dimension.