 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling for Cascading Bandits
Paper and Code
Oct 02, 2018

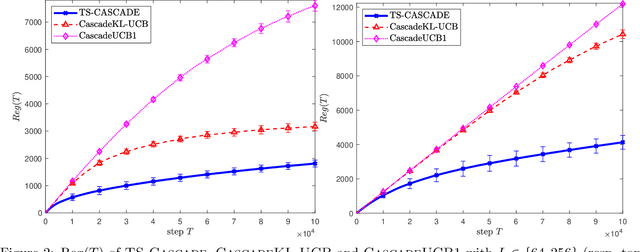

We design and analyze TS-Cascade, a Thompson sampling algorithm for the cascading bandit problem. In TS-Cascade, Bayesian estimates of the click probability are constructed using a univariate Gaussian; this leads to a more efficient exploration procedure vis-\`a-vis existing UCB-based approaches. We also incorporate the empirical variance of each item's click probability into the Bayesian updates. These two novel features allow us to prove an expected regret bound of the form $\tilde{O}(\sqrt{KLT})$ where $L$ and $K$ are the number of ground items and the number of items in the chosen list respectively and $T\ge L$ is the number of Thompson sampling update steps. This matches the state-of-the-art regret bounds for UCB-based algorithms. More importantly, it is the first theoretical guarantee on a Thompson sampling algorithm for any stochastic combinatorial bandit problem model with partial feedback. Empirical experiments demonstrate superiority of TS-Cascade compared to existing UCB-based procedures in terms of the expected cumulative regret and the time complexity.