 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHG: Transformer with Hyperbolic Geometry
Paper and Code
Jun 01, 2021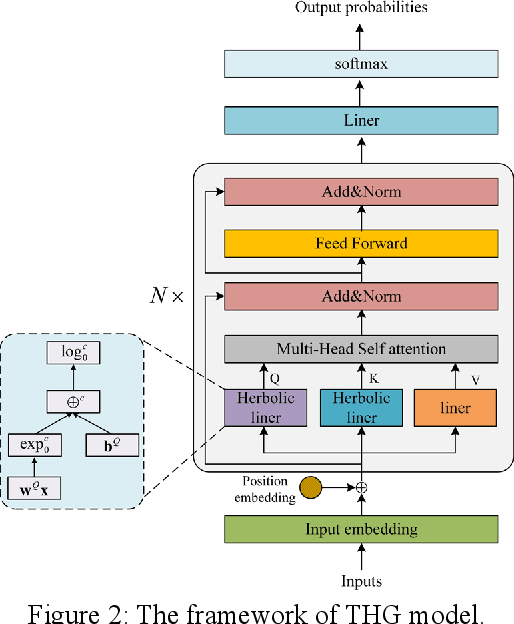

Transformer model architectures have become an indispensable staple in deep learning lately for their effectiveness across a range of tasks. Recently, a surge of "X-former" models have been proposed which improve upon the original Transformer architecture. However, most of these variants make changes only around the quadratic time and memory complexity of self-attention, i.e. the dot product between the query and the key. What's more, they are calculate solely in Euclidean space. In this work, we propose a novel Transformer with Hyperbolic Geometry (THG) model, which take the advantage of both Euclidean space and Hyperbolic space. THG makes improvements in linear transformations of self-attention, which are applied on the input sequence to get the query and the key, with the proposed hyperbolic linear. Extensive experiments on sequence labeling task, machine reading comprehension task and classification task demonstrate the effectiveness and generalizability of our model. It also demonstrates THG could alleviate overfitting.