 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThere is more to graphs than meets the eye: Learning universal features with self-supervision
Paper and Code
May 31, 2023

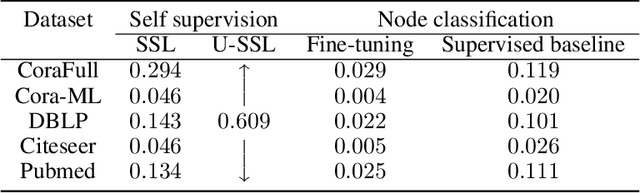

We study the problem of learning universal features across multiple graphs through self-supervision. Graph self supervised learning has been shown to facilitate representation learning, and produce competitive models compared to supervised baselines. However, existing methods of self-supervision learn features from one graph, and thus, produce models that are specialized to a particular graph. We hypothesize that leveraging multiple graphs of the same type/class can improve the quality of learnt representations in the model by extracting features that are universal to the class of graphs. We adopt a transformer backbone that acts as a universal representation learning module for multiple graphs. We leverage neighborhood aggregation coupled with graph-specific embedding generator to transform disparate node embeddings from multiple graphs to a common space for the universal backbone. We learn both universal and graph-specific parameters in an end-to-end manner. Our experiments reveal that leveraging multiple graphs of the same type -- citation networks -- improves the quality of representations and results in better performance on downstream node classification task compared to self-supervision with one graph. The results of our study improve the state-of-the-art in graph self-supervised learning, and bridge the gap between self-supervised and supervised performance.