 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory II: Landscape of the Empirical Risk in Deep Learning
Paper and Code
Jun 22, 2017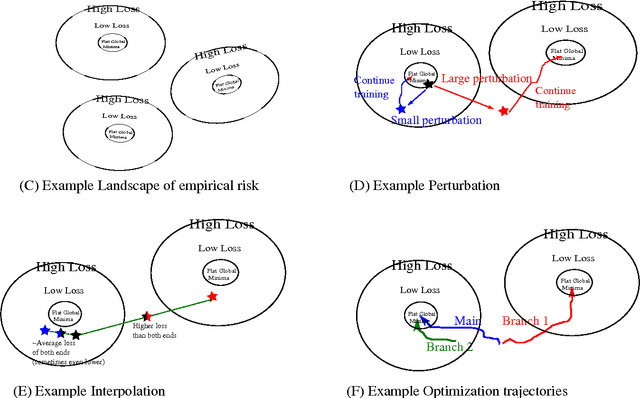

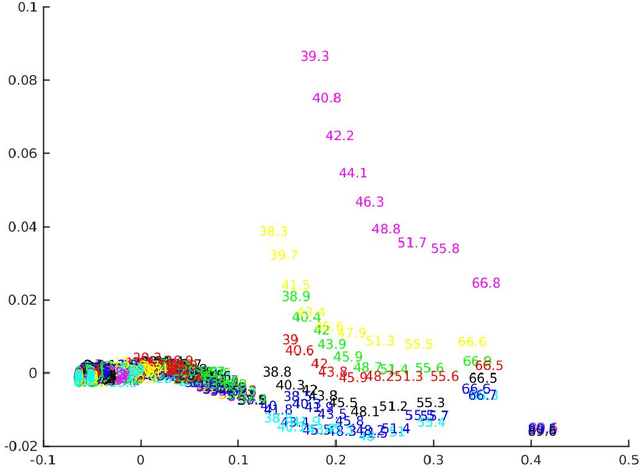

Previous theoretical work on deep learning and neural network optimization tend to focus on avoiding saddle points and local minima. However, the practical observation is that, at least in the case of the most successful Deep Convolutional Neural Networks (DCNNs), practitioners can always increase the network size to fit the training data (an extreme example would be [1]). The most successful DCNNs such as VGG and ResNets are best used with a degree of "overparametrization". In this work, we characterize with a mix of theory and experiments, the landscape of the empirical risk of overparametrized DCNNs. We first prove in the regression framework the existence of a large number of degenerate global minimizers with zero empirical error (modulo inconsistent equations). The argument that relies on the use of Bezout theorem is rigorous when the RELUs are replaced by a polynomial nonlinearity (which empirically works as well). As described in our Theory III [2] paper, the same minimizers are degenerate and thus very likely to be found by SGD that will furthermore select with higher probability the most robust zero-minimizer. We further experimentally explored and visualized the landscape of empirical risk of a DCNN on CIFAR-10 during the entire training process and especially the global minima. Finally, based on our theoretical and experimental results, we propose an intuitive model of the landscape of DCNN's empirical loss surface, which might not be as complicated as people commonly believe.