 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Z-loss: a shift and scale invariant classification loss belonging to the Spherical Family
Paper and Code
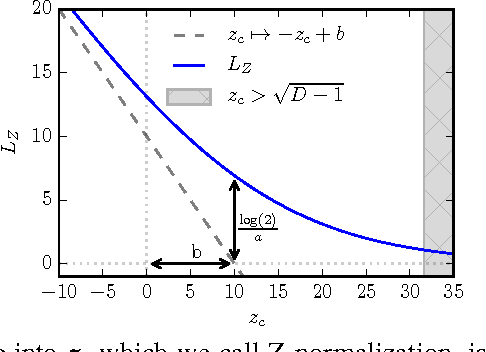

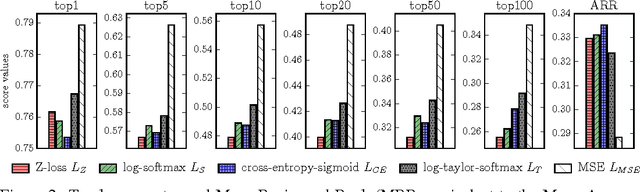
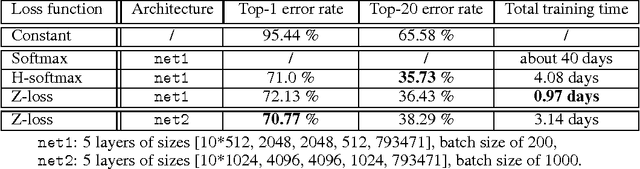
Despite being the standard loss function to train multi-class neural networks, the log-softmax has two potential limitations. First, it involves computations that scale linearly with the number of output classes, which can restrict the size of problems we are able to tackle with current hardware. Second, it remains unclear how close it matches the task loss such as the top-k error rate or other non-differentiable evaluation metrics which we aim to optimize ultimately. In this paper, we introduce an alternative classification loss function, the Z-loss, which is designed to address these two issues. Unlike the log-softmax, it has the desirable property of belonging to the spherical loss family (Vincent et al., 2015), a class of loss functions for which training can be performed very efficiently with a complexity independent of the number of output classes. We show experimentally that it significantly outperforms the other spherical loss functions previously investigated. Furthermore, we show on a word language modeling task that it also outperforms the log-softmax with respect to certain ranking scores, such as top-k scores, suggesting that the Z-loss has the flexibility to better match the task loss. These qualities thus makes the Z-loss an appealing candidate to train very efficiently large output networks such as word-language models or other extreme classification problems. On the One Billion Word (Chelba et al., 2014) dataset, we are able to train a model with the Z-loss 40 times faster than the log-softmax and more than 4 times faster than the hierarchical softmax.