Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe unreasonable effectiveness of the forget gate
Paper and Code
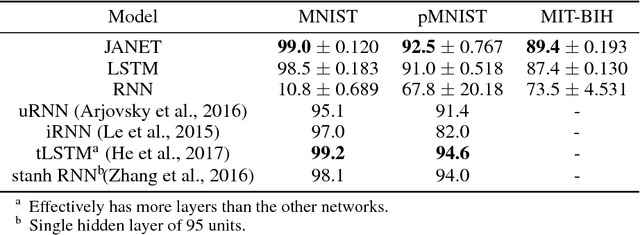
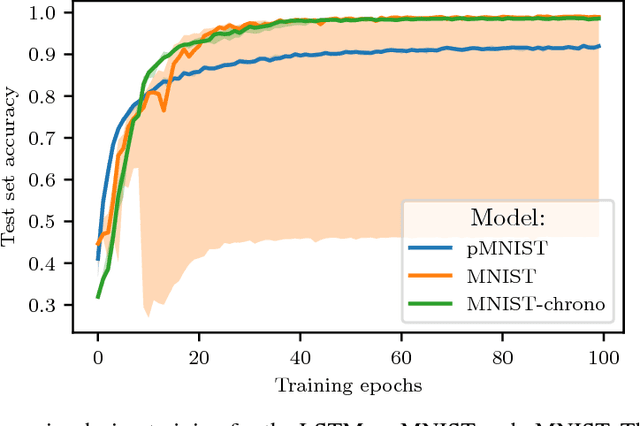
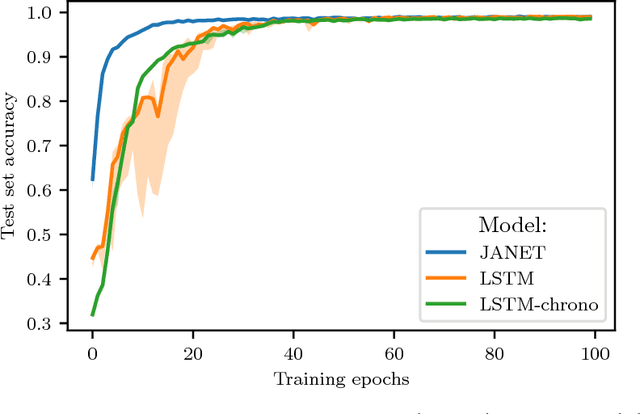
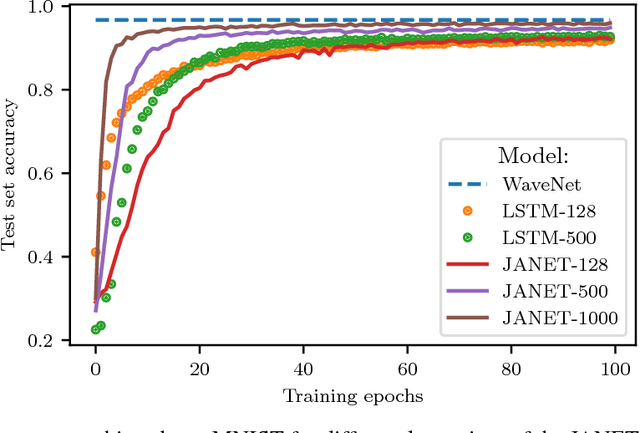
Given the success of the gated recurrent unit, a natural question is whether all the gates of the long short-term memory (LSTM) network are necessary. Previous research has shown that the forget gate is one of the most important gates in the LSTM. Here we show that a forget-gate-only version of the LSTM with chrono-initialized biases, not only provides computational savings but outperforms the standard LSTM on multiple benchmark datasets and competes with some of the best contemporary models. Our proposed network, the JANET, achieves accuracies of 99% and 92.5% on the MNIST and pMNIST datasets, outperforming the standard LSTM which yields accuracies of 98.5% and 91%.
* Corrected LSTM gradient derivations. Added link to code
View paper on