 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RELX Dataset and Matching the Multilingual Blanks for Cross-Lingual Relation Classification
Paper and Code
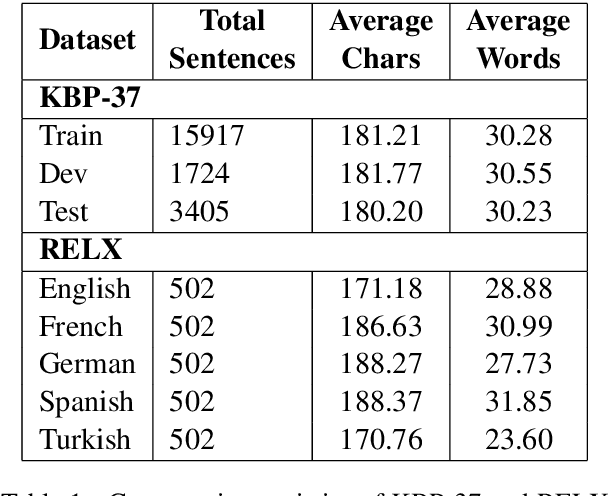
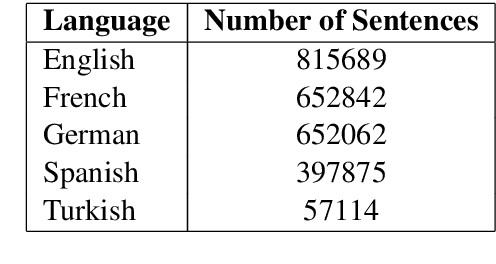
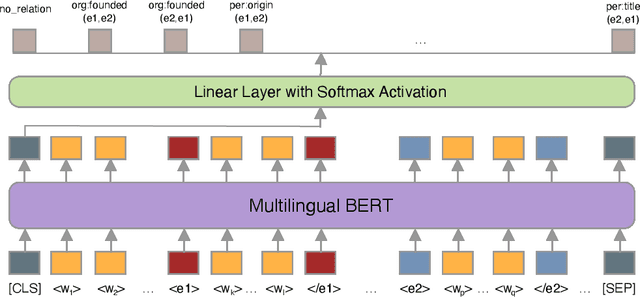

Relation classification is one of the key topics in information extraction, which can be used to construct knowledge bases or to provide useful information for question answering. Current approaches for relation classification are mainly focused on the English language and require lots of training data with human annotations. Creating and annotating a large amount of training data for low-resource languages is impractical and expensive. To overcome this issue, we propose two cross-lingual relation classification models: a baseline model based on Multilingual BERT and a new multilingual pretraining setup, which significantly improves the baseline with distant supervision. For evaluation, we introduce a new public benchmark dataset for cross-lingual relation classification in English, French, German, Spanish, and Turkish, called RELX. We also provide the RELX-Distant dataset, which includes hundreds of thousands of sentences with relations from Wikipedia and Wikidata collected by distant supervision for these languages. Our code and data are available at: https://github.com/boun-tabi/RELX