Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Potential of the Return Distribution for Exploration in RL
Paper and Code

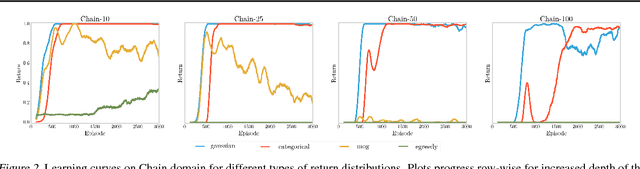
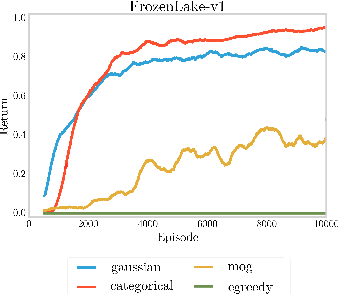
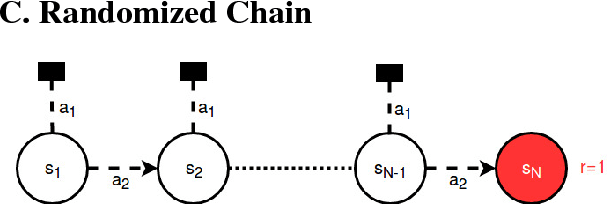
This paper studies the potential of the return distribution for exploration in deterministic reinforcement learning (RL) environments. We study network losses and propagation mechanisms for Gaussian, Categorical and Gaussian mixture distributions. Combined with exploration policies that leverage this return distribution, we solve, for example, a randomized Chain task of length 100, which has not been reported before when learning with neural networks.
* Published at the Exploration in Reinforcement Learning Workshop at
the 35th International Conference on Machine Learning, Stockholm, Sweden
View paper on