 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"The Pedestrian next to the Lamppost" Adaptive Object Graphs for Better Instantaneous Mapping
Paper and Code
Apr 06, 2022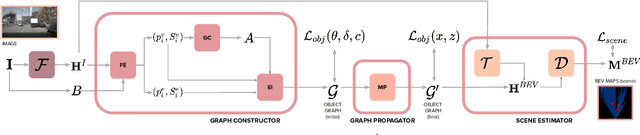

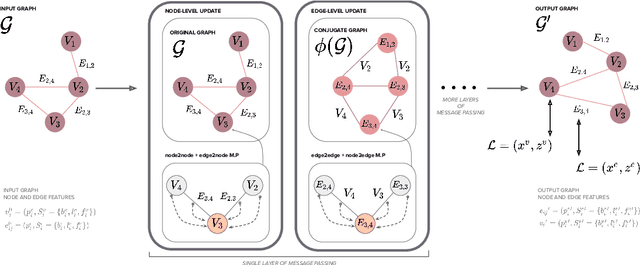

Estimating a semantically segmented bird's-eye-view (BEV) map from a single image has become a popular technique for autonomous control and navigation. However, they show an increase in localization error with distance from the camera. While such an increase in error is entirely expected - localization is harder at distance - much of the drop in performance can be attributed to the cues used by current texture-based models, in particular, they make heavy use of object-ground intersections (such as shadows), which become increasingly sparse and uncertain for distant objects. In this work, we address these shortcomings in BEV-mapping by learning the spatial relationship between objects in a scene. We propose a graph neural network which predicts BEV objects from a monocular image by spatially reasoning about an object within the context of other objects. Our approach sets a new state-of-the-art in BEV estimation from monocular images across three large-scale datasets, including a 50% relative improvement for objects on nuScenes.