 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Omniglot Challenge: A 3-Year Progress Report
Paper and Code
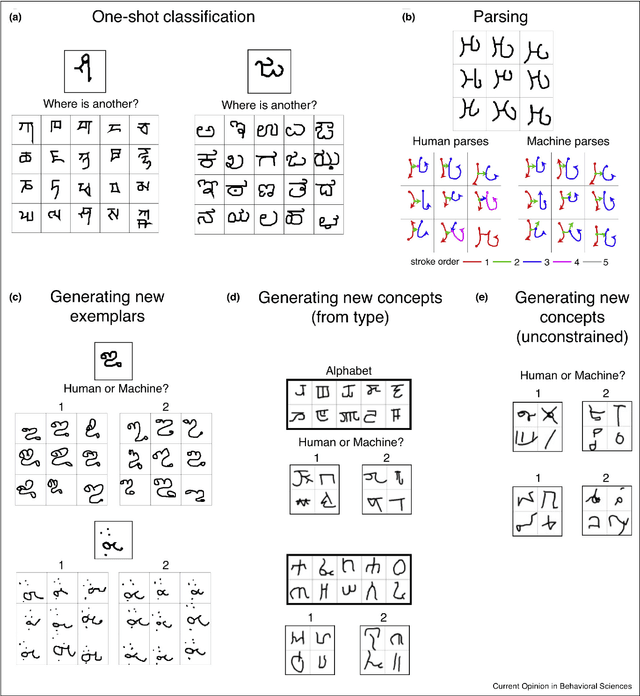

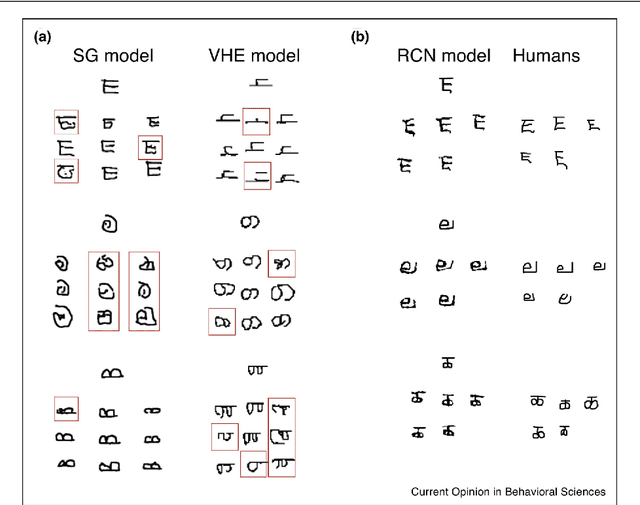
Three years ago, we released the Omniglot dataset for developing more human-like learning algorithms. Omniglot is a one-shot learning challenge, inspired by how people can learn a new concept from just one or a few examples. Along with the dataset, we proposed a suite of five challenge tasks and a computational model based on probabilistic program induction that addresses them. The computational model, although powerful, was not meant to be the final word on Omniglot; we hoped that the machine learning community would both build on our work and develop novel approaches to tackling the challenge. In the time since, we have been pleased to see the wide adoption of Omniglot and notable technical progress. There has been genuine progress on one-shot classification, but it has been difficult to measure since researchers have adopted different splits and training procedures that make the task easier. The other four tasks, while essential components of human conceptual understanding, have received considerably less attention. We review the progress so far and conclude that neural networks are still far from human-like concept learning on Omniglot, a challenge that requires performing all of the tasks with a single model. We also discuss new tasks to stimulate further progress.