 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe OLAC Metadata Set and Controlled Vocabularies
Paper and Code
May 21, 2001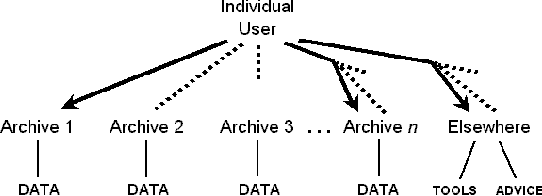
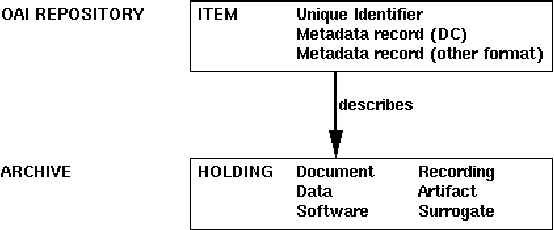
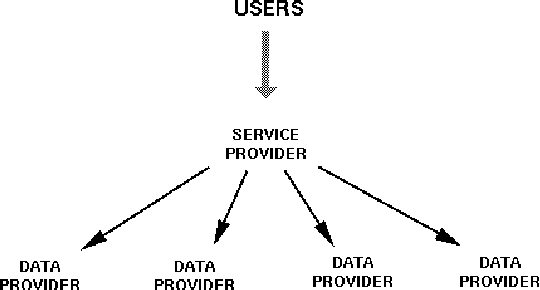

As language data and associated technologies proliferate and as the language resources community rapidly expands, it has become difficult to locate and reuse existing resources. Are there any lexical resources for such-and-such a language? What tool can work with transcripts in this particular format? What is a good format to use for linguistic data of this type? Questions like these dominate many mailing lists, since web search engines are an unreliable way to find language resources. This paper describes a new digital infrastructure for language resource discovery, based on the Open Archives Initiative, and called OLAC -- the Open Language Archives Community. The OLAC Metadata Set and the associated controlled vocabularies facilitate consistent description and focussed searching. We report progress on the metadata set and controlled vocabularies, describing current issues and soliciting input from the language resources community.