 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe mRMR variable selection method: a comparative study for functional data
Paper and Code
Jul 13, 2015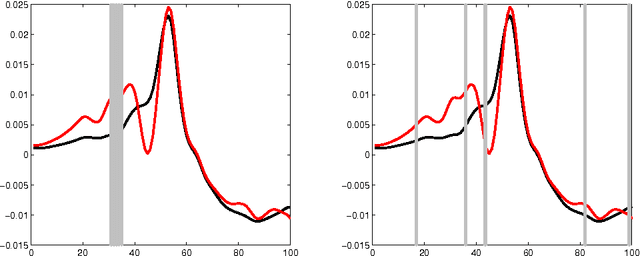
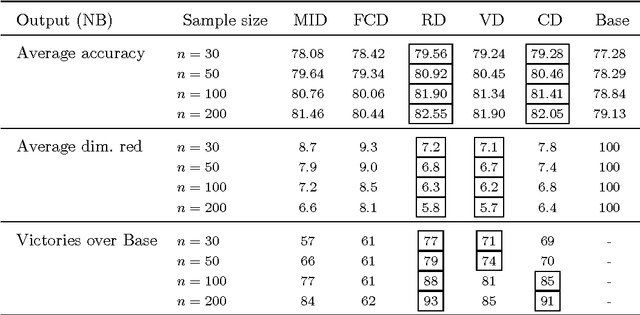
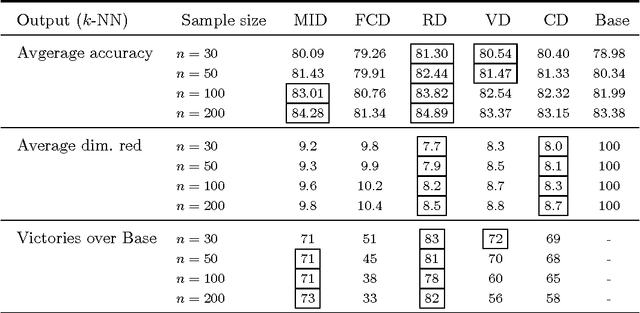

The use of variable selection methods is particularly appealing in statistical problems with functional data. The obvious general criterion for variable selection is to choose the `most representative' or `most relevant' variables. However, it is also clear that a purely relevance-oriented criterion could lead to select many redundant variables. The mRMR (minimum Redundance Maximum Relevance) procedure, proposed by Ding and Peng (2005) and Peng et al. (2005) is an algorithm to systematically perform variable selection, achieving a reasonable trade-off between relevance and redundancy. In its original form, this procedure is based on the use of the so-called mutual information criterion to assess relevance and redundancy. Keeping the focus on functional data problems, we propose here a modified version of the mRMR method, obtained by replacing the mutual information by the new association measure (called distance correlation) suggested by Sz\'ekely et al. (2007). We have also performed an extensive simulation study, including 1600 functional experiments (100 functional models $\times$ 4 sample sizes $\times$ 4 classifiers) and three real-data examples aimed at comparing the different versions of the mRMR methodology. The results are quite conclusive in favor of the new proposed alternative.