 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LORACs prior for VAEs: Letting the Trees Speak for the Data
Paper and Code

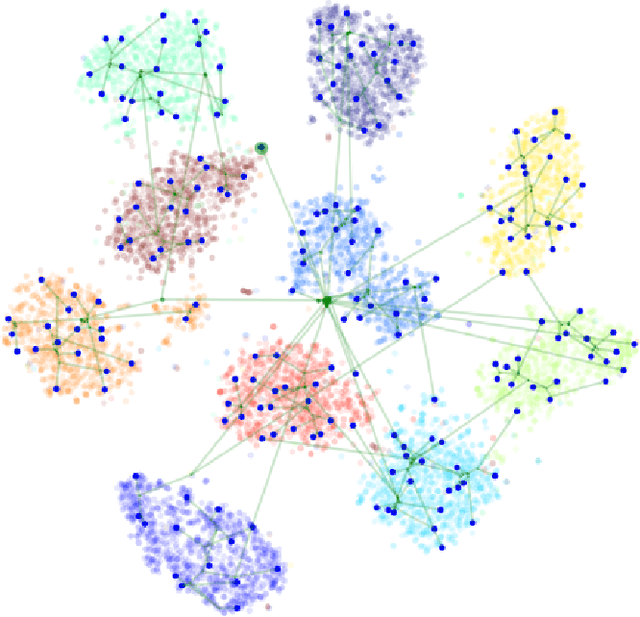
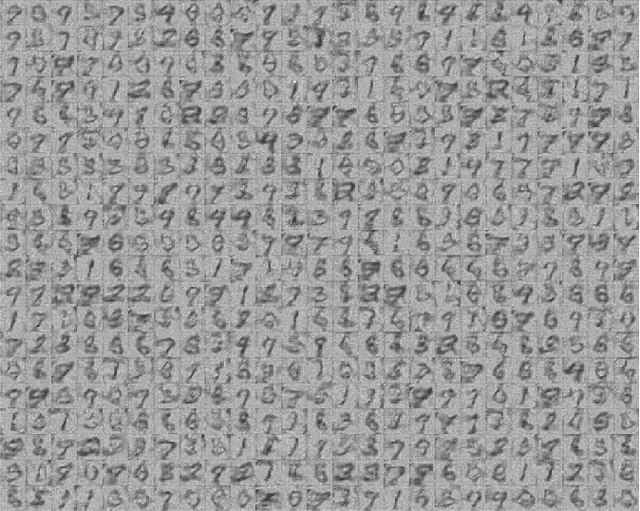

In variational autoencoders, the prior on the latent codes $z$ is often treated as an afterthought, but the prior shapes the kind of latent representation that the model learns. If the goal is to learn a representation that is interpretable and useful, then the prior should reflect the ways in which the high-level factors that describe the data vary. The "default" prior is an isotropic normal, but if the natural factors of variation in the dataset exhibit discrete structure or are not independent, then the isotropic-normal prior will actually encourage learning representations that mask this structure. To alleviate this problem, we propose using a flexible Bayesian nonparametric hierarchical clustering prior based on the time-marginalized coalescent (TMC). To scale learning to large datasets, we develop a new inducing-point approximation and inference algorithm. We then apply the method without supervision to several datasets and examine the interpretability and practical performance of the inferred hierarchies and learned latent space.