 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of Pan Privacy and Shuffle Privacy for Learning and Estimation
Paper and Code
Sep 23, 2020
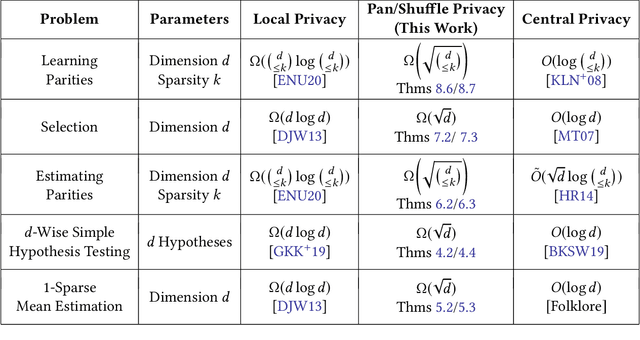
There has been a recent wave of interest in intermediate trust models for differential privacy that eliminate the need for a fully trusted central data collector, but overcome the limitations of local differential privacy. This interest has led to the introduction of the shuffle model (Cheu et al., EUROCRYPT 2019; Erlingsson et al., SODA 2019) and revisiting the pan-private model (Dwork et al., ITCS 2010). The message of this line of work is that, for a variety of low-dimensional problems---such as counts, means, and histograms---these intermediate models offer nearly as much power as central differential privacy. However, there has been considerably less success using these models for high-dimensional learning and estimation problems. In this work, we show that, for a variety of high-dimensional learning and estimation problems, both the shuffle model and the pan-private model inherently incur an exponential price in sample complexity relative to the central model. For example, we show that, private agnostic learning of parity functions over $d$ bits requires $\Omega(2^{d/2})$ samples in these models, and privately selecting the most common attribute from a set of $d$ choices requires $\Omega(d^{1/2})$ samples, both of which are exponential separations from the central model. Our work gives the first non-trivial lower bounds for these problems for both the pan-private model and the general multi-message shuffle model.