 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Influence of Context on Dialogue Act Recognition
Paper and Code
Jan 09, 2017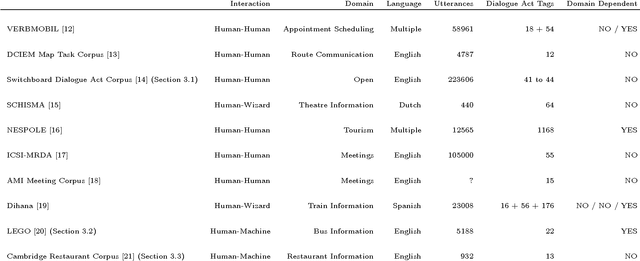
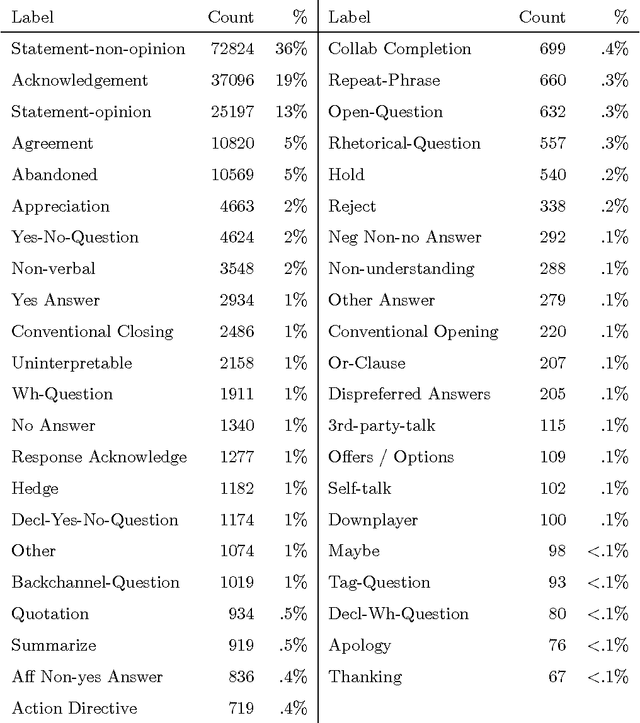
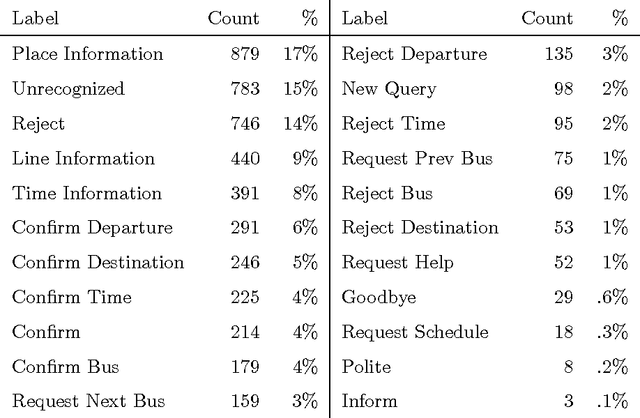
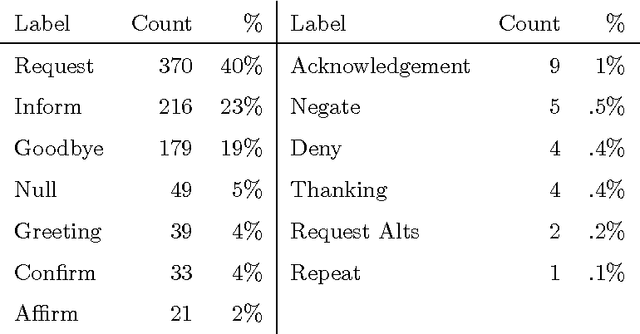
This article presents an analysis of the influence of context information on dialog act recognition. We performed experiments on the widely explored Switchboard corpus, as well as on data annotated according to the recent ISO 24617-2 standard. The latter was obtained from the Tilburg DialogBank and through the mapping of the annotations of a subset of the Let's Go corpus. We used a classification approach based on SVMs, which had proved successful in previous work and allowed us to limit the amount of context information provided. This way, we were able to observe the influence patterns as the amount of context information increased. Our base features consisted of n-grams, punctuation, and wh-words. Context information was obtained from one to five preceding segments and provided either as n-grams or dialog act classifications, with the latter typically leading to better results and more stable influence patterns. In addition to the conclusions about the importance and influence of context information, our experiments on the Switchboard corpus also led to results that advanced the state-of-the-art on the dialog act recognition task on that corpus. Furthermore, the results obtained on data annotated according to the ISO 24617-2 standard define a baseline for future work and contribute for the standardization of experiments in the area.