 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Influence of Audio on Video Memorability with an Audio Gestalt Regulated Video Memorability System
Paper and Code
Apr 23, 2021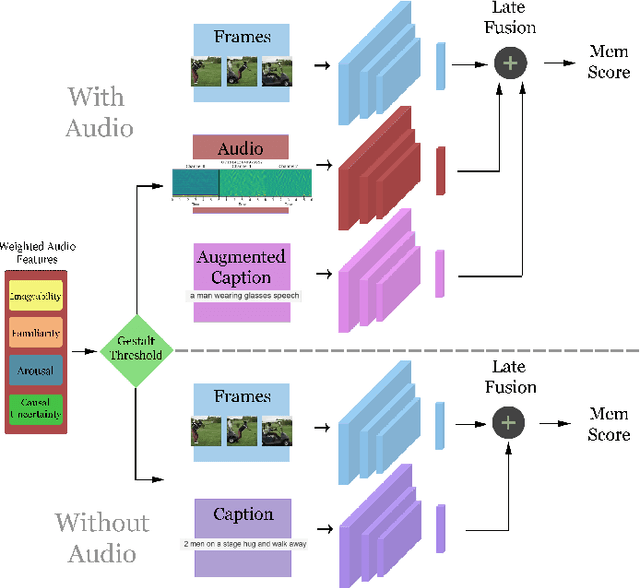
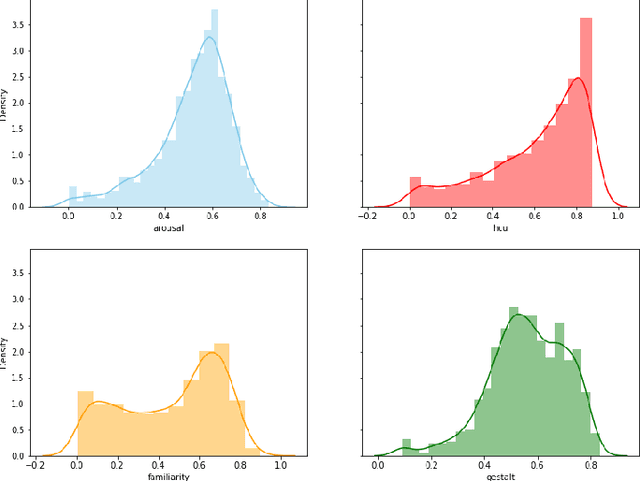
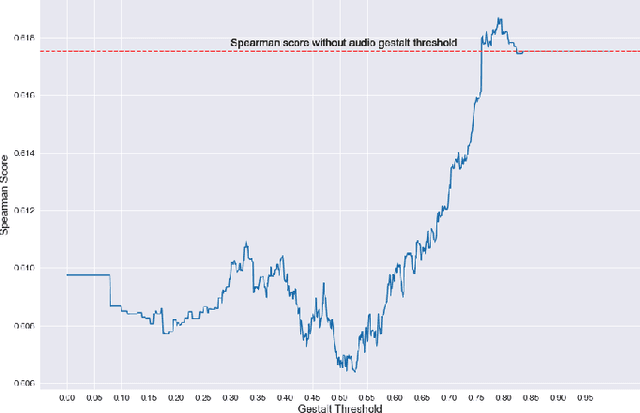

Memories are the tethering threads that tie us to the world, and memorability is the measure of their tensile strength. The threads of memory are spun from fibres of many modalities, obscuring the contribution of a single fibre to a thread's overall tensile strength. Unfurling these fibres is the key to understanding the nature of their interaction, and how we can ultimately create more meaningful media content. In this paper, we examine the influence of audio on video recognition memorability, finding evidence to suggest that it can facilitate overall video recognition memorability rich in high-level (gestalt) audio features. We introduce a novel multimodal deep learning-based late-fusion system that uses audio gestalt to estimate the influence of a given video's audio on its overall short-term recognition memorability, and selectively leverages audio features to make a prediction accordingly. We benchmark our audio gestalt based system on the Memento10k short-term video memorability dataset, achieving top-2 state-of-the-art results.