 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe gap between theory and practice in function approximation with deep neural networks
Paper and Code
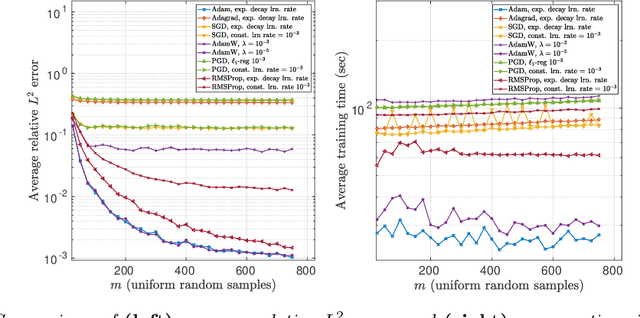



Deep learning (DL) is transforming whole industries as complicated decision-making processes are being automated by Deep Neural Networks (DNNs) trained on real-world data. Driven in part by a rapidly-expanding literature on DNN approximation theory showing that DNNs can approximate a rich variety of functions, these tools are increasingly being considered for problems in scientific computing. Yet, unlike more traditional algorithms in this field, relatively little is known about DNNs from the principles of numerical analysis, namely, stability, accuracy, computational efficiency and sample complexity. In this paper we introduce a computational framework for examining DNNs in practice, and use it to study their empirical performance with regard to these issues. We examine the performance of DNNs of different widths and depths on a variety of test functions in various dimensions, including smooth and piecewise smooth functions. We also compare DL against best-in-class methods for smooth function approximation based on compressed sensing. Our main conclusion is that there is a crucial gap between the approximation theory of DNNs and their practical performance, with trained DNNs performing relatively poorly on functions for which there are strong approximation results (e.g. smooth functions), yet performing well in comparison to best-in-class methods for other functions. Finally, we present a novel practical existence theorem, which asserts the existence of a DNN architecture and training procedure which offers the same performance as current best-in-class schemes. This result indicates the potential for practical DNN approximation, and the need for future research into practical architecture design and training strategies.