 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Empty Signifier Problem: Towards Clearer Paradigms for Operationalising "Alignment" in Large Language Models
Paper and Code
Oct 03, 2023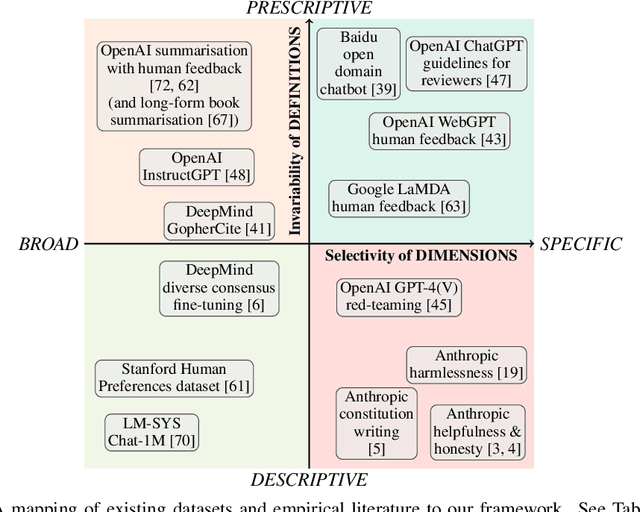
In this paper, we address the concept of "alignment" in large language models (LLMs) through the lens of post-structuralist socio-political theory, specifically examining its parallels to empty signifiers. To establish a shared vocabulary around how abstract concepts of alignment are operationalised in empirical datasets, we propose a framework that demarcates: 1) which dimensions of model behaviour are considered important, then 2) how meanings and definitions are ascribed to these dimensions, and by whom. We situate existing empirical literature and provide guidance on deciding which paradigm to follow. Through this framework, we aim to foster a culture of transparency and critical evaluation, aiding the community in navigating the complexities of aligning LLMs with human populations.