 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ecological Fallacy in Annotation: Modelling Human Label Variation goes beyond Sociodemographics
Paper and Code
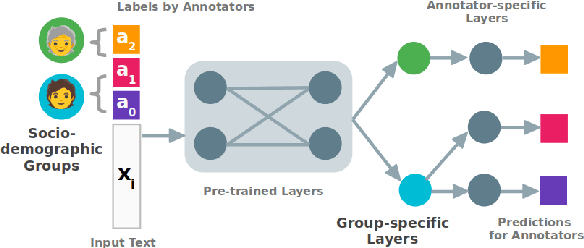
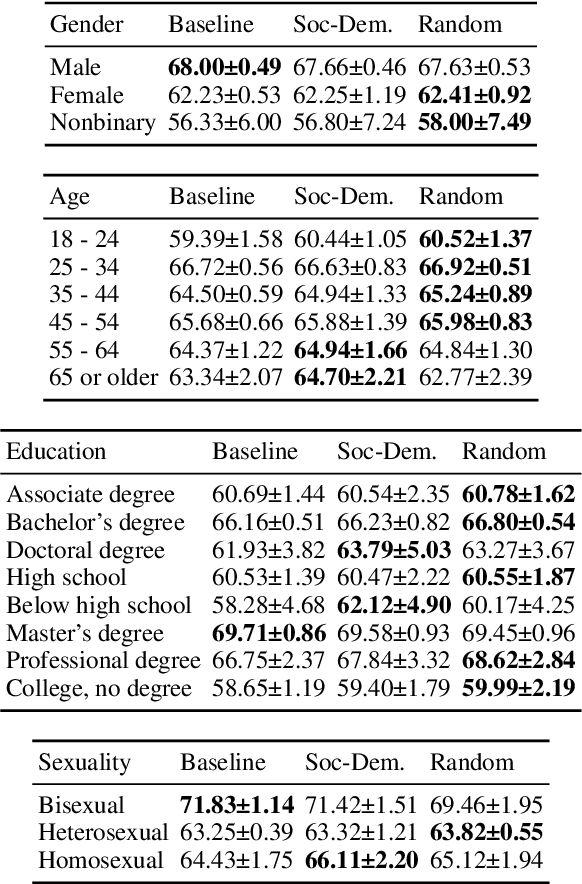


Many NLP tasks exhibit human label variation, where different annotators give different labels to the same texts. This variation is known to depend, at least in part, on the sociodemographics of annotators. Recent research aims to model individual annotator behaviour rather than predicting aggregated labels, and we would expect that sociodemographic information is useful for these models. On the other hand, the ecological fallacy states that aggregate group behaviour, such as the behaviour of the average female annotator, does not necessarily explain individual behaviour. To account for sociodemographics in models of individual annotator behaviour, we introduce group-specific layers to multi-annotator models. In a series of experiments for toxic content detection, we find that explicitly accounting for sociodemographic attributes in this way does not significantly improve model performance. This result shows that individual annotation behaviour depends on much more than just sociodemographics.