 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dependence of Frequency Distributions on Multiple Meanings of Words, Codes and Signs
Paper and Code
Sep 28, 2017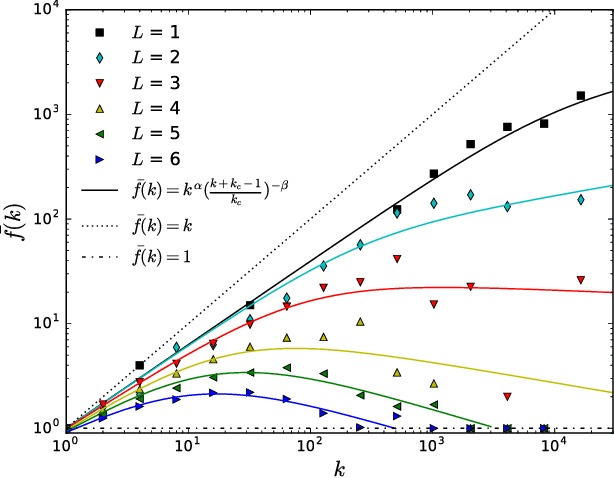
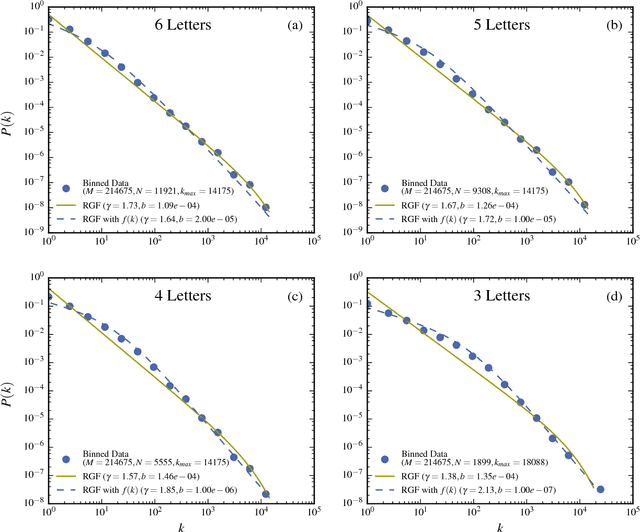
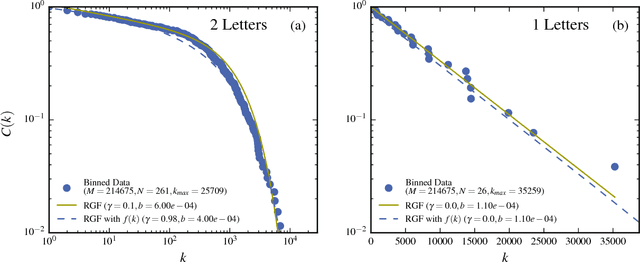
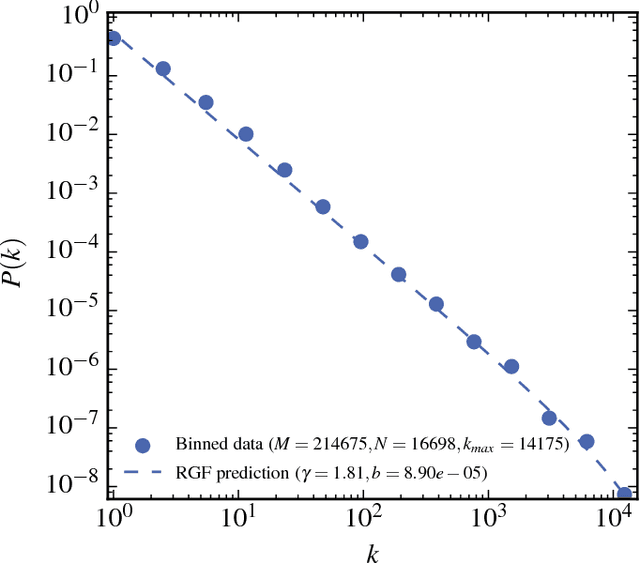
The dependence of the frequency distributions due to multiple meanings of words in a text is investigated by deleting letters. By coding the words with fewer letters the number of meanings per coded word increases. This increase is measured and used as an input in a predictive theory. For a text written in English, the word-frequency distribution is broad and fat-tailed, whereas if the words are only represented by their first letter the distribution becomes exponential. Both distribution are well predicted by the theory, as is the whole sequence obtained by consecutively representing the words by the first L=6,5,4,3,2,1 letters. Comparisons of texts written by Chinese characters and the same texts written by letter-codes are made and the similarity of the corresponding frequency-distributions are interpreted as a consequence of the multiple meanings of Chinese characters. This further implies that the difference of the shape for word-frequencies for an English text written by letters and a Chinese text written by Chinese characters is due to the coding and not to the language per se.