 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe capacity of feedforward neural networks
Paper and Code
Jan 02, 2019


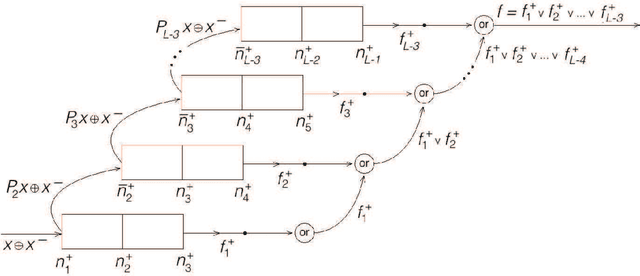
A long standing open problem in the theory of neural networks is the development of quantitative methods to estimate and compare the capabilities of different architectures. Here we define the capacity of an architecture by the binary logarithm of the number of functions it can compute, as the synaptic weights are varied. The capacity is an upper bound on the number of bits that can be "communicated" from the training data to the architecture over the learning channel. We study the capacity of layered, fully-connected, architectures of linear threshold neurons with $L$ layers of size $n_1,n_2, \ldots, n_L$ and show that in essence the capacity is given by a cubic polynomial in the layer sizes: $C(n_1,\ldots, n_L)=\sum_{k=1}^{L-1} \min(n_1,\ldots,n_k)n_kn_{k+1}$. In proving the main result, we also develop new techniques (multiplexing, enrichment, and stacking) as well as new bounds on the capacity of finite sets. We use the main result to identify architectures with maximal or minimal capacity under a number of natural constraints. This leads to the notion of structural regularization for deep architectures. While in general, everything else being equal, shallow networks compute more functions than deep networks, the functions computed by deep networks are more regular and "interesting".