 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Bottleneck Simulator: A Model-based Deep Reinforcement Learning Approach
Paper and Code
Jul 12, 2018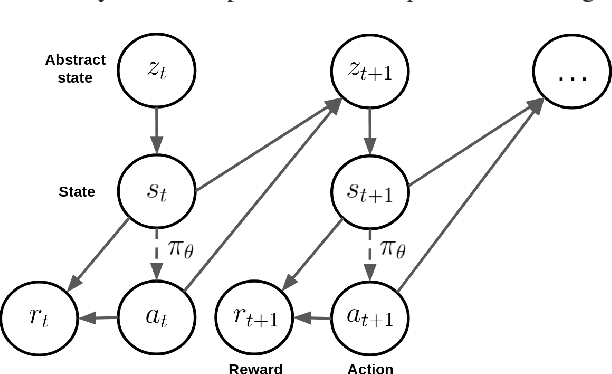

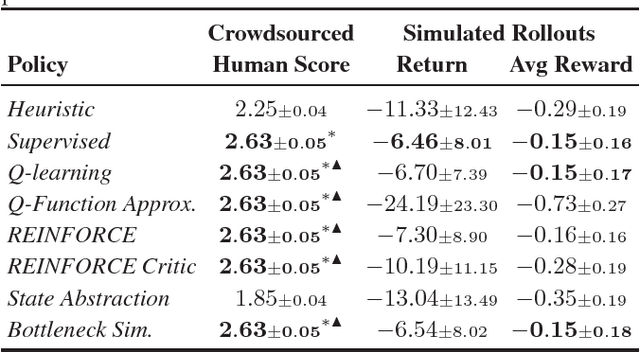
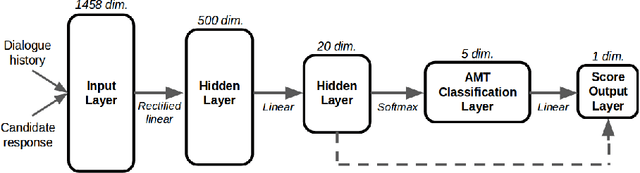
Deep reinforcement learning has recently shown many impressive successes. However, one major obstacle towards applying such methods to real-world problems is their lack of data-efficiency. To this end, we propose the Bottleneck Simulator: a model-based reinforcement learning method which combines a learned, factorized transition model of the environment with rollout simulations to learn an effective policy from few examples. The learned transition model employs an abstract, discrete (bottleneck) state, which increases sample efficiency by reducing the number of model parameters and by exploiting structural properties of the environment. We provide a mathematical analysis of the Bottleneck Simulator in terms of fixed points of the learned policy, which reveals how performance is affected by four distinct sources of error: an error related to the abstract space structure, an error related to the transition model estimation variance, an error related to the transition model estimation bias, and an error related to the transition model class bias. Finally, we evaluate the Bottleneck Simulator on two natural language processing tasks: a text adventure game and a real-world, complex dialogue response selection task. On both tasks, the Bottleneck Simulator yields excellent performance beating competing approaches.