 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Approximation of the Dissimilarity Projection
Paper and Code
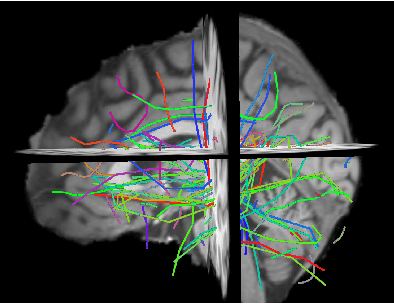

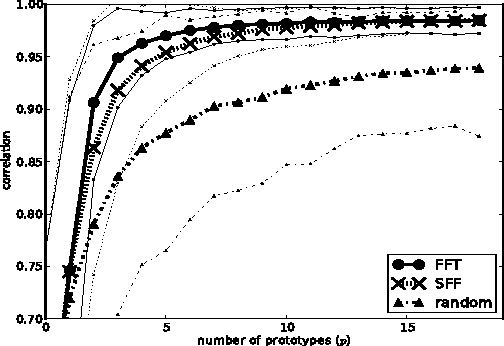
Diffusion magnetic resonance imaging (dMRI) data allow to reconstruct the 3D pathways of axons within the white matter of the brain as a tractography. The analysis of tractographies has drawn attention from the machine learning and pattern recognition communities providing novel challenges such as finding an appropriate representation space for the data. Many of the current learning algorithms require the input to be from a vectorial space. This requirement contrasts with the intrinsic nature of the tractography because its basic elements, called streamlines or tracks, have different lengths and different number of points and for this reason they cannot be directly represented in a common vectorial space. In this work we propose the adoption of the dissimilarity representation which is an Euclidean embedding technique defined by selecting a set of streamlines called prototypes and then mapping any new streamline to the vector of distances from prototypes. We investigate the degree of approximation of this projection under different prototype selection policies and prototype set sizes in order to characterise its use on tractography data. Additionally we propose the use of a scalable approximation of the most effective prototype selection policy that provides fast and accurate dissimilarity approximations of complete tractographies.