 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe All Relevant Feature Selection using Random Forest
Paper and Code
Jun 25, 2011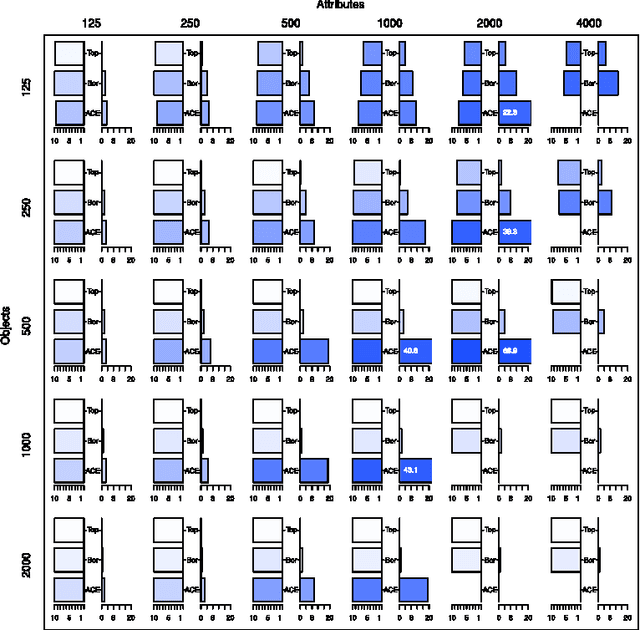
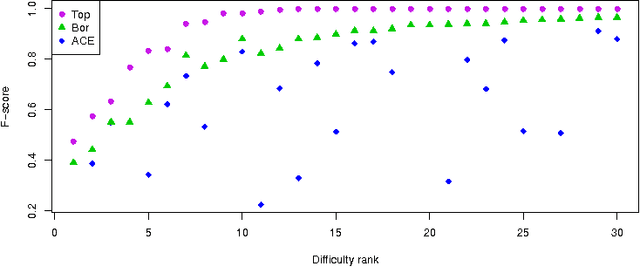
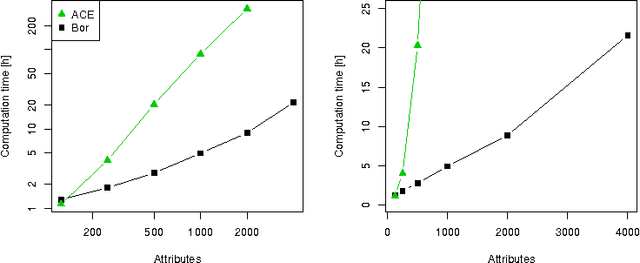
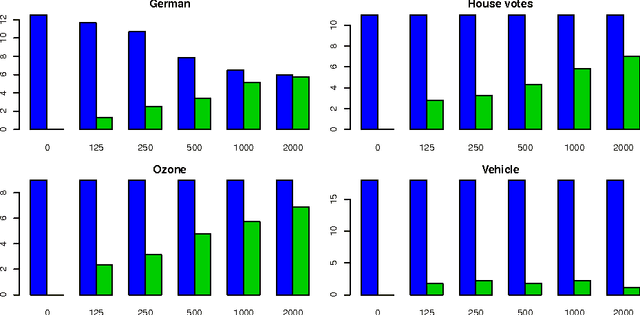
In this paper we examine the application of the random forest classifier for the all relevant feature selection problem. To this end we first examine two recently proposed all relevant feature selection algorithms, both being a random forest wrappers, on a series of synthetic data sets with varying size. We show that reasonable accuracy of predictions can be achieved and that heuristic algorithms that were designed to handle the all relevant problem, have performance that is close to that of the reference ideal algorithm. Then, we apply one of the algorithms to four families of semi-synthetic data sets to assess how the properties of particular data set influence results of feature selection. Finally we test the procedure using a well-known gene expression data set. The relevance of nearly all previously established important genes was confirmed, moreover the relevance of several new ones is discovered.