 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe advantages of multiple classes for reducing overfitting from test set reuse
Paper and Code
May 24, 2019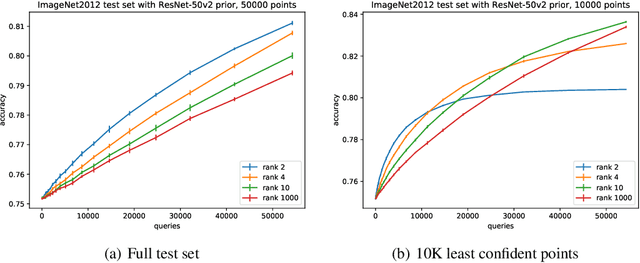
Excessive reuse of holdout data can lead to overfitting. However, there is little concrete evidence of significant overfitting due to holdout reuse in popular multiclass benchmarks today. Known results show that, in the worst-case, revealing the accuracy of $k$ adaptively chosen classifiers on a data set of size $n$ allows to create a classifier with bias of $\Theta(\sqrt{k/n})$ for any binary prediction problem. We show a new upper bound of $\tilde O(\max\{\sqrt{k\log(n)/(mn)},k/n\})$ on the worst-case bias that any attack can achieve in a prediction problem with $m$ classes. Moreover, we present an efficient attack that achieve a bias of $\Omega(\sqrt{k/(m^2 n)})$ and improves on previous work for the binary setting ($m=2$). We also present an inefficient attack that achieves a bias of $\tilde\Omega(k/n)$. Complementing our theoretical work, we give new practical attacks to stress-test multiclass benchmarks by aiming to create as large a bias as possible with a given number of queries. Our experiments show that the additional uncertainty of prediction with a large number of classes indeed mitigates the effect of our best attacks. Our work extends developments in understanding overfitting due to adaptive data analysis to multiclass prediction problems. It also bears out the surprising fact that multiclass prediction problems are significantly more robust to overfitting when reusing a test (or holdout) dataset. This offers an explanation as to why popular multiclass prediction benchmarks, such as ImageNet, may enjoy a longer lifespan than what intuition from literature on binary classification suggests.