 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Unlearning Gives a False Sense of Unlearning
Paper and Code
Jun 19, 2024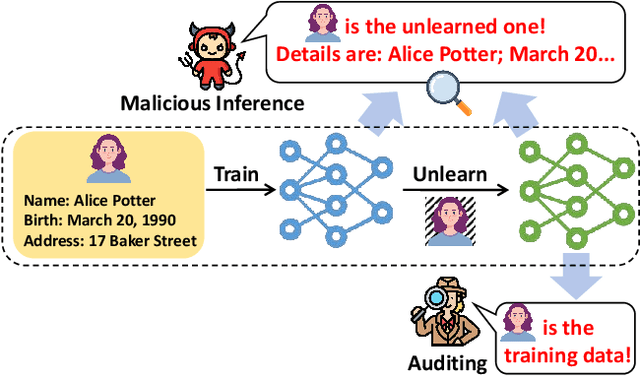
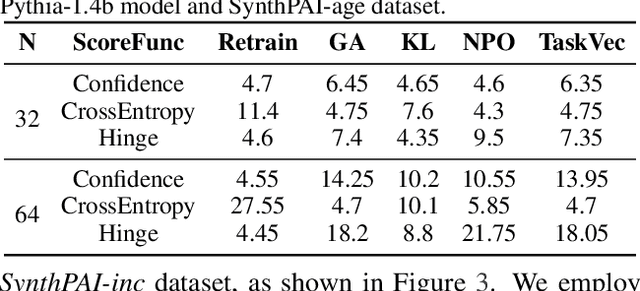
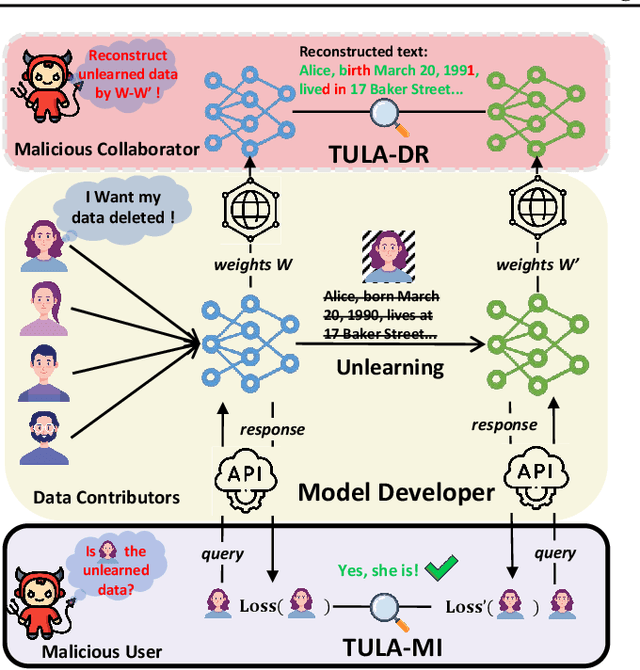

Language models (LMs) are susceptible to "memorizing" training data, including a large amount of private or copyright-protected content. To safeguard the right to be forgotten (RTBF), machine unlearning has emerged as a promising method for LMs to efficiently "forget" sensitive training content and mitigate knowledge leakage risks. However, despite its good intentions, could the unlearning mechanism be counterproductive? In this paper, we propose the Textual Unlearning Leakage Attack (TULA), where an adversary can infer information about the unlearned data only by accessing the models before and after unlearning. Furthermore, we present variants of TULA in both black-box and white-box scenarios. Through various experimental results, we critically demonstrate that machine unlearning amplifies the risk of knowledge leakage from LMs. Specifically, TULA can increase an adversary's ability to infer membership information about the unlearned data by more than 20% in black-box scenario. Moreover, TULA can even reconstruct the unlearned data directly with more than 60% accuracy with white-box access. Our work is the first to reveal that machine unlearning in LMs can inversely create greater knowledge risks and inspire the development of more secure unlearning mechanisms.