 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Backdoor Attacks with Iterative Trigger Injection
Paper and Code
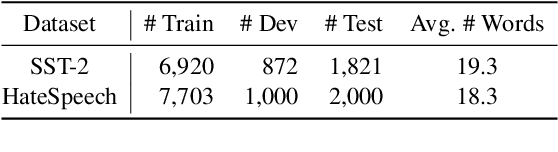
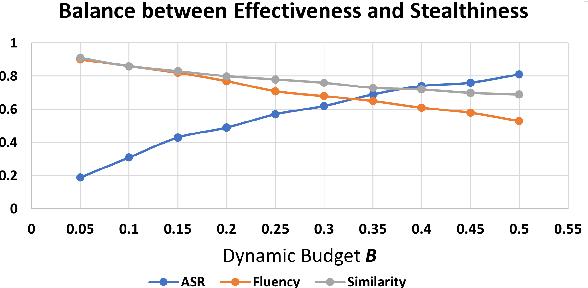
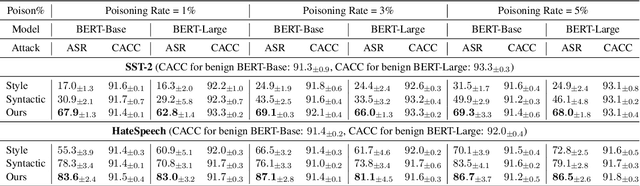
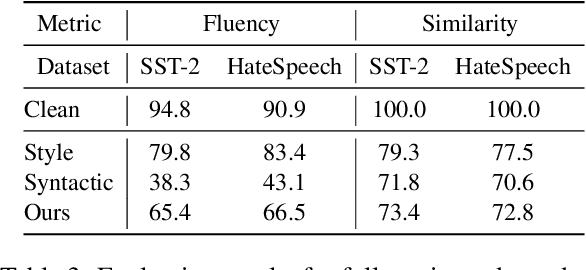
The backdoor attack has become an emerging threat for Natural Language Processing (NLP) systems. A victim model trained on poisoned data can be embedded with a "backdoor", making it predict the adversary-specified output (e.g., the positive sentiment label) on inputs satisfying the trigger pattern (e.g., containing a certain keyword). In this paper, we demonstrate that it's possible to design an effective and stealthy backdoor attack by iteratively injecting "triggers" into a small set of training data. While all triggers are common words that fit into the context, our poisoning process strongly associates them with the target label, forming the model backdoor. Experiments on sentiment analysis and hate speech detection show that our proposed attack is both stealthy and effective, raising alarm on the usage of untrusted training data. We further propose a defense method to combat this threat.