 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Scene: Generating Abstract Scenes from Textual Descriptions
Paper and Code

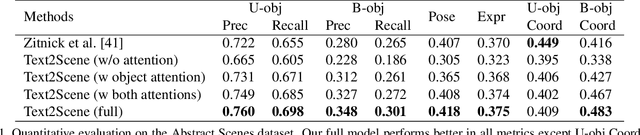
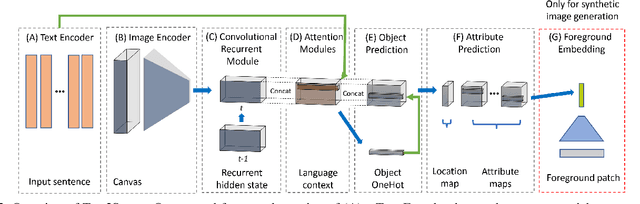

In this paper, we propose an end-to-end model that learns to interpret natural language describing a scene to generate an abstract pictorial representation. The pictorial representations generated by our model comprise the spatial distribution and attributes of the objects in the described scene. Our model uses a sequence-to-sequence network with a double attentive mechanism and introduces a regularization strategy. These scene representations can be sampled from our model similarly as in language-generation models. We show that the proposed model, initially designed to handle the generation of cartoon-like pictorial representations in the Abstract Scenes Dataset, can also handle, under minimal modifications, the generation of semantic layouts corresponding to real images in the COCO dataset. Human evaluations using a visual entailment task show that pictorial representations generated with our full model can entail at least one out of three input visual descriptions 94% of the times, and at least two out of three 62% of the times for each image.