 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Audio Grounding Based Novel Metric for Evaluating Audio Caption Similarity
Paper and Code
Oct 03, 2022
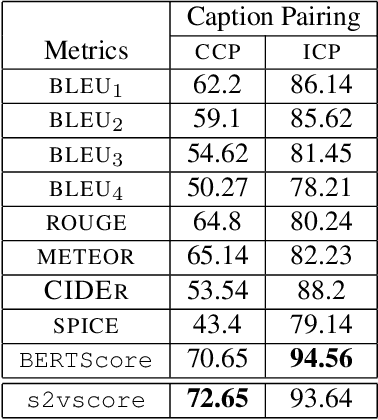
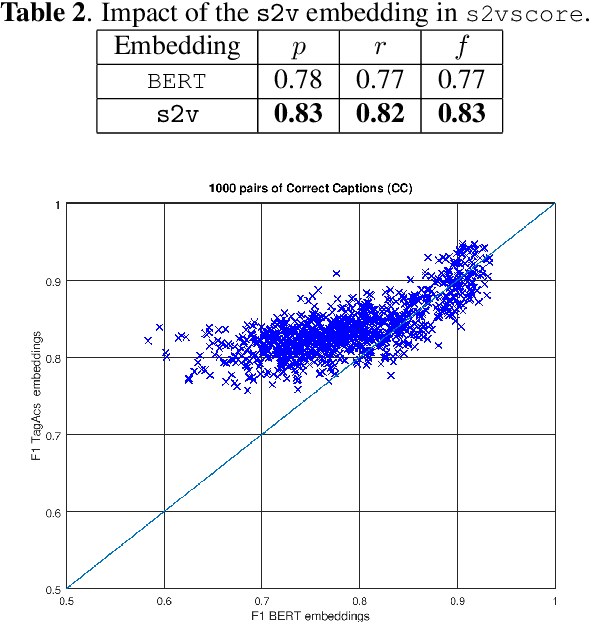
Automatic Audio Captioning (AAC) refers to the task of translating an audio sample into a natural language (NL) text that describes the audio events, source of the events and their relationships. Unlike NL text generation tasks, which rely on metrics like BLEU, ROUGE, METEOR based on lexical semantics for evaluation, the AAC evaluation metric requires an ability to map NL text (phrases) that correspond to similar sounds in addition lexical semantics. Current metrics used for evaluation of AAC tasks lack an understanding of the perceived properties of sound represented by text. In this paper, wepropose a novel metric based on Text-to-Audio Grounding (TAG), which is, useful for evaluating cross modal tasks like AAC. Experiments on publicly available AAC data-set shows our evaluation metric to perform better compared to existing metrics used in NL text and image captioning literature.