 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Adaptive Vision-and-Language Navigation
Paper and Code
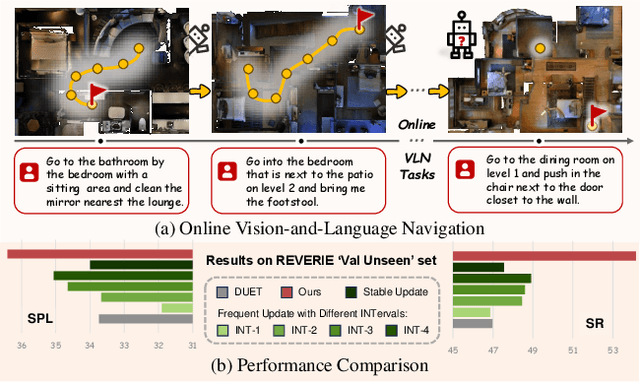
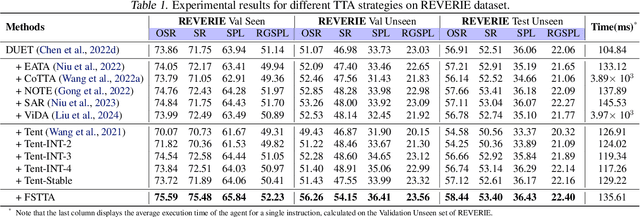
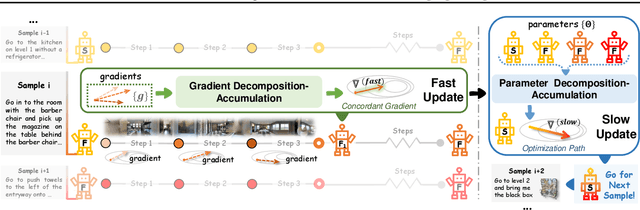
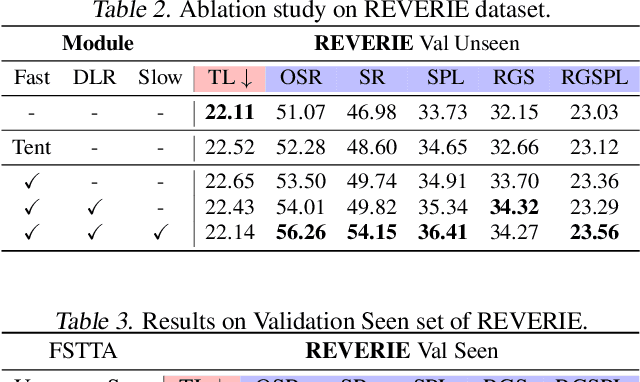
Vision-and-Language Navigation (VLN) has witnessed significant advancements in recent years, largely attributed to meticulously curated datasets and proficiently trained models. Nevertheless, when tested in diverse environments, the trained models inevitably encounter significant shifts in data distribution, highlighting that relying solely on pre-trained and fixed navigation models is insufficient. To enhance models' generalization ability, test-time adaptation (TTA) demonstrates significant potential in the computer vision field by leveraging unlabeled test samples for model updates. However, simply applying existing TTA methods to the VLN task cannot well handle the adaptability-stability dilemma of VLN models, i.e., frequent updates can result in drastic changes in model parameters, while occasional updates can make the models ill-equipped to handle dynamically changing environments. Therefore, we propose a Fast-Slow Test-Time Adaptation (FSTTA) approach for VLN by performing decomposition-accumulation analysis for both gradients and parameters in a unified framework. Specifically, in the fast update phase, gradients generated during the recent multi-step navigation process are decomposed into components with varying levels of consistency. Then, these components are adaptively accumulated to pinpoint a concordant direction for fast model adaptation. In the slow update phase, historically recorded parameters are gathered, and a similar decomposition-accumulation analysis is conducted to revert the model to a stable state. Extensive experiments show that our method obtains impressive performance gains on four popular benchmarks.