 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerm Revealing: Furthering Quantization at Run Time on Quantized DNNs
Paper and Code
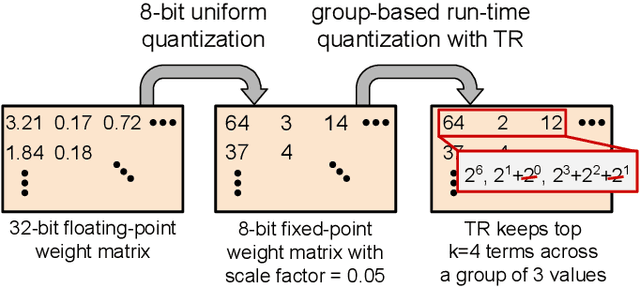
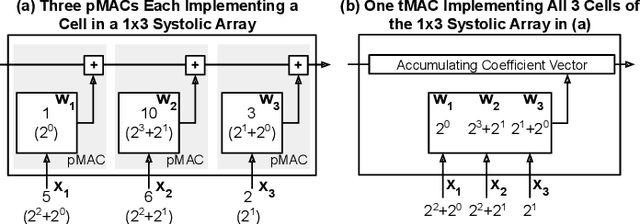
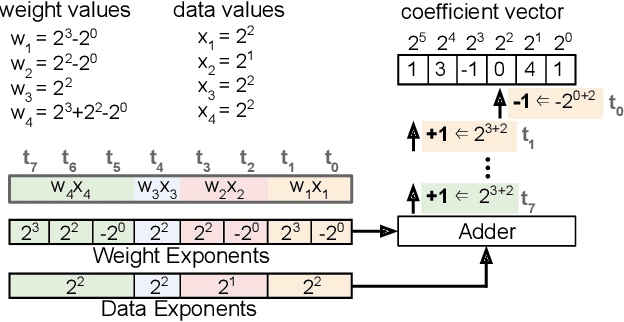
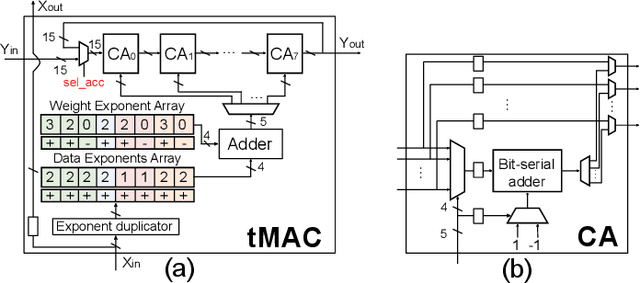
We present a novel technique, called Term Revealing (TR), for furthering quantization at run time for improved performance of Deep Neural Networks (DNNs) already quantized with conventional quantization methods. TR operates on power-of-two terms in binary expressions of values. In computing a dot-product computation, TR dynamically selects a fixed number of largest terms to use from the values of the two vectors in the dot product. By exploiting normal-like weight and data distributions typically present in DNNs, TR has a minimal impact on DNN model performance (i.e., accuracy or perplexity). We use TR to facilitate tightly synchronized processor arrays, such as systolic arrays, for efficient parallel processing. We show an FPGA implementation that can use a small number of control bits to switch between conventional quantization and TR-enabled quantization with a negligible delay. To enhance TR efficiency further, we use a signed digit representation (SDR), as opposed to classic binary encoding with only nonnegative power-of-two terms. To perform conversion from binary to SDR, we develop an efficient encoding method called HESE (Hybrid Encoding for Signed Expressions) that can be performed in one pass looking at only two bits at a time. We evaluate TR with HESE encoded values on an MLP for MNIST, multiple CNNs for ImageNet, and an LSTM for Wikitext-2, and show significant reductions in inference computations (between 3-10x) compared to conventional quantization for the same level of model performance.