 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Valued Common and Individual Feature Extraction: Multi-dimensional Perspective
Paper and Code
Nov 01, 2017
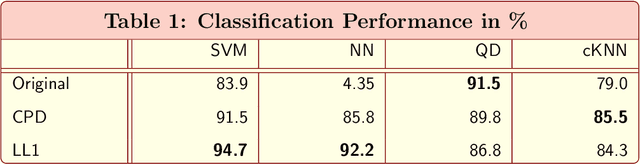
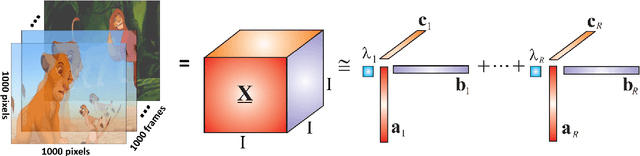

A novel method for common and individual feature analysis from exceedingly large-scale data is proposed, in order to ensure the tractability of both the computation and storage and thus mitigate the curse of dimensionality, a major bottleneck in modern data science. This is achieved by making use of the inherent redundancy in so-called multi-block data structures, which represent multiple observations of the same phenomenon taken at different times, angles or recording conditions. Upon providing an intrinsic link between the properties of the outer vector product and extracted features in tensor decompositions (TDs), the proposed common and individual information extraction from multi-block data is performed through imposing physical meaning to otherwise unconstrained factorisation approaches. This is shown to dramatically reduce the dimensionality of search spaces for subsequent classification procedures and to yield greatly enhanced accuracy. Simulations on a multi-class classification task of large-scale extraction of individual features from a collection of partially related real-world images demonstrate the advantages of the "blessing of dimensionality" associated with TDs.